2. Bayesin päätösteoria
|
|
|
- Tuomo Uotila
- 8 vuotta sitten
- Katselukertoja:
Transkriptio
1 13 / Bayesin päätösteoria 2.1. Johdanto Bayesin päätösteorian (Bayesian decision theory) avulla on mahdollista johtaa optimaalisia tilastollisia luokittelijoita. Perustuu todennäköisyyslaskentaan ja olettaa tarvittavat todennäköisyydet tunnetuiksi. Merkitään asiaintilaa (state of nature) symbolilla ω kalanlajittelun esimerkissä tarkoittaa tarkasteltavan kalan lajia: ω ω 1, kun kala on meriahven ja ω ω 2, kun kala on lohi koska asiaintila on niin ennustamaton, tulkitaan ω muuttujaksi, joka täytyy kuvailla probabilistisesti Asiaintila ω on tässä diskreettiarvoinen, koska sillä on vain kaksi tilaa. Sen tiloihin liittyy a priori todennnäköisyydet P(ω j ), jotka kuvastavat tilojen suhteellisia esiintymiskertoja populaatiossa: P(ω 1 ): meriahvenien suhteellinen osuus saaliskaloissa P(ω 2 ): lohien suhteellinen osuus saaliskaloissa jos muita tiloja ei ole, P(ω 1 ) + P(ω 2 ) 1 Mikäli luokittelijalla ei ole muuta tietoa kaloista kuin a priori todennäköisyydet, päätössääntö on yksinkertainen: päätä ω 1 jos P(ω 1 ) > P(ω 2 ), muutoin päätä ω 2 Tavallisesti käytettävissä on muutakin tietoa, nimittäin aiemmin mainittuja kohteita luonnehtivia piirteitä. Olkoon x kalan kirkkautta kuvaava jatkuva-arvoinen satunnaismuuttuja, jonka jakauma p( x ω) riippuu asiaintilasta. Jakaumaa kutsutaan luokkaehdolliseksi todennäköisyystiheysfunktioksi (class-conditional probability density function): satunnaismuuttujan x tiheysfunktio oletuksella että asiaintila on ω. Tällöin tiheysfunktioiden p( x ω 1 ) ja p( x ω 2 ) välinen ero kuvastaa näiden kalalajien kirkkauseroja populaatiossa (kuva alla):
2 14 / 99 Tiheysfunktioita voidaan käyttää hyväksi luokittelussa Bayesin kaavan avulla. Tämän johtamiseksi kirjoitetaan ensin yhteistodennäköisyystiheys (joint probability density) sille, että hahmo kuuluu luokkaan ω j JA sillä on piirteen arvo x: p( ω j, x) P( ω j x)p( x) p( x ω j )P( ω j ) Tästä saadaan kuuluisa Bayesin kaava (Bayes formula): P( ω j x) p( x ω j )P( ω j ) p( x) Tämä voidaan ilmaista sanallisesti seuraavasti: p( x ω j )P( ω j ) i 1 p( x ω i )P( ω i ) likelihood prior posterior evidence likelihood : uskottavuus a priori todennäköisyydestä lasketaan siis a posteriori todennäköisyys
3 15 / 99 A posteriori todennäköisyys ω j, kun piirrearvo x on havaittu. P( ω j x) kuvastaa todennäköisyyttä, että asiaintila on Tiheysfunktiota p( x ω) kutsutaan uskottavuusfunktioksi (likelihood function). Se kuvastaa asiaintilan ω j uskottavuutta suhteessa mittausarvoon x siten, että mitä suurempi funktion arvo on piirreavaruuden pisteessä x, sitä uskottavammin asiaintila on ω j. Nimittäjässä esiintyvä termi p(x) on lähinnä skaalaustekijä, jolla varmistetaan se, että posteriori-todennäköisyydet summautuvat arvoon 1 kaikkialla piirreavaruudessa. Se kuvastaa muuttujan x tiheyttä yli koko populaation. Tästä saadaan Bayesin päätössääntö (Bayes decision rule): Päätä ω 1 jos P( ω 1 x) > P( ω 2 x), muutoin päätä ω 2 Ekvivalentti päätössääntö: Päätä ω 1 jos p( x ω 1 )P( ω 1 ) > p( x ω 2 )P( ω 2 ), muutoin päätä ω 2
4 16 / 99 Bayesin päätössääntö minimoi luokitteluvirheen keskimääräisen todennäköisyyden, mikä nähdään seuraavasti: Virheen keskimääräinen todennäköisyys saadaan lausekkeesta: P( virhe) P( virhe, x) dx Tämä saa pienimmän arvonsa, kun kohdissa x. P( virhe x) P( virhe x)p( x) dx saa pienimmän arvonsa kaikissa Yleisesti ottaen, kun havaitaan piirrearvo x, virheellisen luokittelupäätöksen todennäköisyys on: P( virhe x) Noudatettaessa Bayesin päätössääntöä pätee jokaisessa pisteessä x: Siispä virheen keskimääräinen todennäköisyys saa pienimmän mahdollisen arvonsa käytettäessä Bayesin päätössääntöä! M.O.T. P( ω 1 x), kun päätetään ω 2 P( ω 2 x), kun päätetään ω 1 P( virhe x) min[ P( ω 1 x), P( ω 2 x) ] Mikään muu päätössääntö ei voi alittaa Bayesin luokitteluvirhettä. Mikäli siis todennäköisyydet tunnetaan (priorit ja jakaumat), kannattaa käyttää Bayesin päätössääntöön perustuvaa luokittelijaa. Muut luokittelijat tuottavat korkeintaan yhtä hyviä tuloksia, todennäköisesti huonompia. Käytännön vaikeus on tietysti määrätä todennäköisyydet tarkasti.
5 17 / Bayesin päätösteoria - jatkuva-arvoiset piirremuuttujat Yleistetään edellisen kappaleen tulokset: sallitaan useita piirteitä d-ulotteinen piirrevektori (satunnaismuuttuja) x piirreavaruudessa R d sallitaan useita asiaintiloja { ω 1,..., ω c } sallitaan muitakin toimintoja (action) kuin päätöksenteko asiaintilasta (kuten kieltäytyminen päätöksenteosta, mikäli hahmon luokka ei näytä selvältä) { α 1,..., α a } käyttämällä virheen todennäköisyyttä yleisempää kustannusfunktiota (cost function) kustannusfunktio λ( α i ω j ) ilmaisee kuinka suuri kustannus syntyy tekemällä toiminto α i asiaintilassa ω j Bayesin kaava on samaa muotoa kuin aiemmin: P( ω j x) p( x ω j )P( ω j ) p( x) p( x ω j )P( ω j ) c i 1 p( x ω i )P( ω i ) Oletetaan nyt, että havaitaan piirrevektori x ja halutaan tehdä sen perusteella toiminto α i. Tähän toiminnon tekemiseen liittyvän kustannuksen odotusarvo on: Päätösteoreettisessa terminologiassa kustannuksen odotusarvoa (expected loss) kutsutaan riskiksi (risk), ja suuretta R( α i x) kutsutaan ehdolliseksi riskiksi (conditional risk). Bayesin päätösproseduuri: c R( α i x) λ( α i ω j )P( ω j x) j 1 Valitse se toiminto α i, jota vastaava ehdollinen riski R( α i x) on pienin
6 18 / 99 Bayesin päätössääntö tuottaa optimaalisen suorituskyvyn, mikä nähdään seuraavasti: Ongelmana on löytää kokonaisriskin minimoiva päätössääntö. Yleinen päätössääntö on funktio α(x), joka kertoo mikä toiminto α i { α 1,..., α c } tulee valita kunkin tapauksen x kohdalla. Kokonaisriski on tiettyyn päätössääntöön liittyvä kustannuksen odotusarvo: R R( α( x) ) R( α( x), x) dx R( α( x) x)p( x) dx Kun α(x) päätyy valintaan α i siten, että lauseke saa pienimmän arvonsa. M.O.T. R( α i x) on pienin kaikilla x, ylläoleva Pienintä kokonaisriskiä kutsutaan Bayesin riskiksi (Bayes risk) R*, joka on samalla pienin saavutettavissa oleva riski. Tarkastellaan 2-luokkaista erikoistapausta: R( α 1 x) λ 11 P( ω 1 x) + λ 12 P( ω 2 x) R( α 2 x) λ 21 P( ω 1 x) + λ 22 P( ω 2 x) jossa on yksinkertaistettu merkintöjä käyttämällä λ ij Valitaan siis α 1, jos R( α 1 x) < R( α 2 x), eli jos: λ( α i ω j ) ( λ 21 λ 11 )P( ω 1 x) > ( λ 12 λ 22 )P( ω 2 x) eli ( λ 21 λ 11 )p( x ω 1 )P( ω 1 ) > ( λ 12 λ 22 )p( x ω 2 )P( ω 2 ) eli p( x ω 1 ) ( λ λ 22 ) p( x ω 2 ) ( P ( ω2 ) > λ 21 λ 11 ) P( ω 1 ) Alinta muotoa kutsutaan likelihood ratio -suureeksi ja sen käyttöä päätössääntönä LR-testiksi, jossa verrataan kahden uskottavuusfunktion suhdetta kynnysarvoon.
7 19 / 99 Johdetaan aiemmin esitelty minimivirheluokittelija (minimum-error-rate classifier): Toiminto α i olkoon nyt hahmon luokittelu luokkaan ω i. Oikean ja väärän luokittelun kustannukset olkoon 0-1-kustannusfunktion mukaiset: λ( α i ω j ) 0 i j 1 i j Oikealla päätöksellä ei siis ole kustannuksia, ja kaikki väärät päätökset maksavat saman verran. Tätä kustannusfunktiota vastaava ehdollinen riski on nyt: c R( α i x) λ( α i ω j )P( ω j x) P ω j x 1 P( ω i x) j 1 j i Päätössääntö: eli: eli: Valitse α i, jos Valitse α i, jos Valitse α i, jos R( α i x) < R( α j x) kaikilla j i 1 P( ω i x) < 1 P( ω j x) kaikilla j i P( ω i x) > P( ω j x) kaikilla j i Alla kuva, jossa piirretty LR-suhde edellisen kuvan esimerkille:
8 20 / Luokittelijat, diskriminanttifunktiot ja päätöspinnat Luokittelijat voidaan esittää monella tavalla yhden suosituimmista ollessa diskriminanttifunktiot g i (x), i1,...,c. Suomeksi voidaan käyttää nimeä erottelufunktiot. Jokaiselle luokalle siis suunnitellaan oma diskriminanttifunktio. Luokittelija sijoittaa piirrevektorin x omaavan hahmon luokkaan ω i, jos: g i ( x) > g j ( x) kaikilla j i eli suurimman lukuarvon tuottavan funktion luokkaan. Riskin minimointiin perustuvalle Bayesin luokittelijalle voidaan valita: g i (x) - R( α i x), jolloin suurimman diskriminanttifunktion arvo vastaa pienintä ehdollista riskiä. Minimivirheeseen perustuvalle Bayesin luokittelijalle voidaan valita: g i (x) P( ω i x), jolloin suurimman diskriminanttifunktion arvo vastaa suurinta a posteriori todennäköisyyttä
9 21 / 99 Diskriminanttifunktiota voidaan muokata vaikuttamatta päätössääntöön. Esimerkiksi, toimivasta d-funktiosta g i (x) saadaan uusi muunnoksella f(g i (x)), jossa f() on monotonisesti kasvava funktio. Eräitä suosittuja diskriminanttifunktioita ovat: g i ( x) P( ω i x) p( x ω i )P( ω i ) c j 1 g i ( x) p( x ω i )P( ω i ) p( x ω j )P( ω j ) g i ( x) ln p( x ω i ) + ln P( ω i ) Päätössäännön tarkoitus on jakaa piirreavaruus päätösalueisiin (decision regions) R 1,...,R c. Mikäli siis g i ( x) > g j ( x) kaikilla j i, niin piirevektori x kuuluu päätösalueeseen R i, ja päätössääntö luokittelee hahmon luokkaan ω i. Päätösalueita erottaa toisistaan päätöspinnat (decision boundary):
10 22 / 99 Kaksiluokkaisessa tapauksessa luokittelijaa kutsutaan Englanniksi dichotomizer, joka tulee jakamisesta kahteen osaan. Kahden diskriminanttifunktion sijasta käytetään yhtä, joka määritellään seuraavasti: g( x) g 1 ( x) g 2 ( x) Päätössääntö on: Päätä ω 1, jos g( x) > 0, muutoin päätä ω 2 Usein käytetään seuraavia funktioita: g( x) P( ω 1 x) P( ω 2 x) g( x) ln p ( x ω 1) ln P ( ω 1) p( x ω 2 ) P( ω 2 )
11 23 / Normaalijakauma Bayesin luokittelijan rakenteen määrittelee ehdolliset tiheysfunktiot p( x ω i ) ja prioritodennäköisyydet P(ω i ). Eniten tutkittu tiheysfunktiomuoto on normaalijakauma (normal density, Gaussian), koska sen analyyttinen käsiteltävyys on hyvä ja koska se sopii hyvin mallintamaan usein esiintyvää signaaliin summautunutta kohinaa. Ensialkuun palautetaan mieleen skalaariarvoisen funktion f(x) tilastollisen odotusarvon (expected value) määritelmä, kun x on jatkuva-arvoinen muuttuja: ε[ f( x) ] f( x)p( x) dx Diskreetin muuttujan x D tapauksessa odotusarvo lasketaan kaavalla: Huomaa, että jatkuva muuttujan x tapauksessa käytetään todennäköisyystiheysfunktiota p(x) (pienellä p:llä), kun diskreetin muuttujan x tapauksessa käytetään todennäköisyysjakaumaa (todennäköisyysmassaa) P(x) (isolla P:llä). Jatkuva-arvoisen skalaarimuuttujan x normaalijakauma eli Gaussin jakauma: ε[ f( x) ] f( x)p( x) x D p( x) x µ σ e 2πσ Muuttujan x odotusarvo ja neliöllisen poikkeaman odotusarvo eli varianssi: µ ε[ x ] xp( x) dx σ 2 ε[( x µ ) 2 ] ( x µ ) 2 p( x) dx
12 24 / 99 Usein merkitään p( x) N ( µ, σ 2 ), katso kuva alla: Piirrevektorin tiheysfunktio Monimuuttujainen (multivariate) normaalijakauma p( x) N( m, Σ) : p( x) 1 -- ( x m) t Σ 1 ( x m) e ( 2π) d 2 Σ 1 2, jossa m on x:n d-ulotteinen odotusarvovektori (mean vector), ja Σ on dxdkokoinen kovarianssimatriisi (covariance matrix), Σ ja Σ 1 ovat kovarianssimatriisin determinantti ja käänteismatriisi, yläindeksi t tarkoittaa transpoosia. m ε[ x ] xp( x) dx Σ ε[ ( x m) ( x m) t ] ( x m) ( x m) t p( x) dx
13 25 / 99 Odotusarvo vektorista saadaan ottamalla odotusarvo vektorin komponenteista erikseen: m i ε[ x i ] Kovarianssimatriisin elementti σ ij edustaa komponenttien x i ja x j välistä kovarianssia ja määritellään seuraavasti: σ ij ε[ ( x i m i )( x j m j ) ] Kovarianssimatriisi on aina symmetrinen ja positiivinen semidefiniitti (eli determinantti nolla tai positiivinen). Determinantti on nolla esimerkiksi silloin, kun osa piirrevektorin komponenteista ovat identtisiä tai korreloivat täydellisesti keskenään. Jos komponentit x i ja x j ovat tilastollisesti riippumattomia (statistically independent), elementti σ ij 0. Mutta ei välttämättä toisinpäin, sillä kovarianssianalyysissä arvioidaan lineaarista riippumattomuutta, ja riippuvuuksiahan on olemassa epälineaarisiakin! Diagonaalielementit σ ii σ i 2 ovat komponenttien x i varianssit. Alla esimerkki 2- ulotteisen piirrevektorijoukon kovarianssimatriisista: S 2 σ 11 σ 12 σ 1 σ12 σ 21 σ 2 22 σ 21 σ 2 σ 1 2 σ12 σ 12 σ 2 2 Monimuuttujaisen normaalijakauman määrittelee siis d+d(d+1)/2 parametria, eli odotusarvovektori ja kovarianssimatriisin riippumattomat elementit. Esimerkiksi diskreetin muuttujan x tapauksessa lasketaan näitä suureita vastaavat otoskeskiarvo ja otoskovarianssimatriisi seuraavasti: N 1 x --- x N i i 1 S N x N ( i x) ( x i x) t i 1
14 26 / 99 Alla kuva 2-ulotteisesta Gaussin jakaumasta. Jakauma on vino, koska esimerkkitapauksessa piirteet x 1 ja x 2 korreloivat positiivisesti (esimerkiksi kalan pituus ja paino). Ellipsit kuvastavat pisteitä, joissa r 2 ( x m) t Σ 1 ( x m) vakio Suuretta r kutsutaan Mahalanobis-etäisyydeksi piirrevektorin x ja luokan jakauman odotusarvon m välillä. (Kuvassa odotusarvoa m merkitään symbolilla µ.) Sitä käytetään usein luokittelijoissa mitattaessa sitä kuinka etäällä/lähellä hahmo on eri luokkia, tähän palataan pian. Ellipsien akselit voidaan haluttaessa laskea ominaisarvoanalyysin kautta. Tyypillisesti kuvat piirretään siten, että sisin ellipsi on yhden keskihajonnan (standard deviation) etäisyydellä keskipisteestä, seuraava kahden keskihajonnan, jne.
 ln p( x ω i ) + ln P( ω i ) normaalijakautuneen satunnaismuuttujan x tapauksessa p(")
15 27 / Diskriminanttifunktioita normaalijakaumalle Käytettäessä diskriminanttifunktiona aiemmin esitettyä muotoa g i ( x) ln p( x ω i ) + ln P( ω i ) normaalijakautuneen satunnaismuuttujan x tapauksessa p( x ω i ) N( m i, Σ i ) ja: g i ( x) 1 -- ( x m 2 i ) t 1 d Σ i ( x m i ) -- ln 2π ln Σ i + ln P( ω i ) Tarkastellaan seuraavaksi eräitä usein käytännössä esiintyviä erikoistapauksia Tapaus Σ i σ 2 I Tässä tapauksessa kaikkien luokkien kovarianssimatriisi on identtinen ja on yksikkömatriisin muotoinen päädiagonaalielementin saadessa arvon σ 2. Esim.: Σ σ σ 2 Näin käy jos piirrevektorin komponentit eli piirteet ovat tilastollisesti lineaarisesti riippumattomia ja jokaisen piirteen varianssi on sama σ 2. Geometrisesti tulkittuna tämä tarkoittaa ympyrämäisesti samalla tavalla jakautuneita luokkia, jotka sijaitsevat piirreavaruuden kohdissa m i.
16 28 / 99 Tällöin Σ i σ 2d ja Σ σ 2 I Koska 2. ja 3. termi diskriminanttifunktiossa ovat riippumattomia luokasta, ne eivät vaikuta erottelukykyyn ja voidaan siten jättää pois. Saadaan siis: g i ( x) 2 x m i σ 2 + ln P( ω i ) Ensimmäisen termin osoittajassa esiintyvä lauseke on pisteiden x ja m i välinen Euklidinen etäisyys: d 2 x m i ( x m i ) t ( x m i ) ( x j m ij ) 2 j 1 x 2 x x-m i m i x 1
17 29 / 99 Edellä esitettyä diskriminanttifunktiota voidaan muokata edelleen laskemalla etäisyyslauseke auki, jolloin saadaan: g i ( x) σ 2 x t t t [ x 2m ix + mi mi ] + ln P( ω i ) Termi x t x on sama kaikille luokille, joten se voidaan jättää pois. Merkitään nyt: 1 1 t w i σ 2 m i ja w i σ 2 m imi + ln P( ω i ) Tällöin saadaan muoto, jota kutsutaan lineaariseksi diskriminanttifunktioksi: t g i ( x) w ix + wi0 Lineaarista diskriminanttifunktiota käyttävää luokittelijaa kutsutaan lineaariseksi koneeksi (linear machine). Voidaan osoittaa, että lineaarisella koneella luokkia erottelevina päätöspintoina toimivat hypertasot, jotka voidaan laskea suoraviivaisesti jokaisen luokkaparin i-j välille asettamalla g i (x)g j (x): g i ( x) g j ( x) 0 t t w ix + wi0 w jx wj σ 2 ( m i m j ) t 1 t 1 t x m 2σ 2 imi + ln P( ω i ) m 2σ 2 jmj ln P( ω j ) 0 ( m i m j ) t 1 t t x -- ( m 2 imi m jmj ) σ 2 ln P( ω i ) 0 P( ω j ) ( m i m j ) t 1 x -- ( m 2 i m j ) t m i m j ( m i + m j ) σ 2 ln P ω i ( ) 0 2 P( ω j ) ( m i m j ) t 1 x -- ( m 2 i m j ) t ( m i m j ) t ( m i + m j ) σ 2 ln P ( ω i) ( m 2 P( ω j ) i m j ) 0 m i m i m j m j 2 ( m i m j ) t 1 x -- ( m 2 i + m j ) ln P ( ω i) ( m 2 P( ω j ) i m j ) m i σ 2 m j ( m i m j ) t x x 0 ( ) 0 0 Yhtälö ( m i m j ) t ( x x 0 ) 0 edustaa pisteen x 0 kautta kulkevaa hypertasoa L, joka on kohtisuorassa luokkien i ja j keskipisteitä yhdistävää janaa m i -m j vastaan.
18 30 / 99
19 31 / 99 Mikäli prioritodennäköisyydet ovat yhtäsuuret P(ω i )P(ω j ), lausekkeista nähdään 1 että x 0 -- ( m eli hypertaso kulkee luokkakeskipisteiden puolivälistä. 2 i + m j ) Mikäli P( ω i ) > P( ω j ), leikkauspiste x 0 siirtyy poispäin luokasta ω i. Alla olevassa piirroksessa uusi leikkauspiste on x 0 ja ε>0 tulee lausekkeesta: ε σ ln P ( ω i) m i m P( ω j ) j L x 2 m i m i -m j L x 0 x 0 ε(m i -m j ) m j x 1 Mikäli priorit ovat samat kaikille luokille, diskriminanttifunktiota voidaan yksinkertaistaa edelleen poistamalla vastaavat termit. Lisäksi voidaan poistaa luokasta riippumattomat σ-termit, joten päätössäännöksi saadaan: Päätä ω i mikäli x m i < x m j j i Tätä kutsutaan minimietäisyysluokittelijaksi (minimum distance classifier), jota käytetään monissa sovelluksissa. Tämän luvun perusteella nähdään mitä matemaattisia oletuksia on oltava voimassa, jotta päätössääntö toimisi optimaalisesti.
20 32 / Tapaus Σ i Σ Luokkien kovarianssimatriisit ovat identtiset, mutta muutoin mielivaltaiset. Geometrisen tulkinnan mukaan luokkien muodot on piirreavaruudessa ovat samanlaiset, mutta ne sijaitsevat eri paikoissa m i. Koska osa diskriminanttifunktion termeistä on jälleen luokasta riippumattomia, saadaan yksinkertaistamisen jälkeen: g i ( x) 1 -- ( x m 2 i ) t Σ 1 ( x m i ) ln P( ω i ) Mikäli luokkien priorit ovat samat, saadaan päätössäännöksi yksinkertaistamisen jälkeen: Päätä ω i mikäli ( x m i ) t Σ 1 ( x m i ) < ( x m j ) t Σ 1 ( x m j ) j i Etäisyysmittana käytetään tässä Mahalanobis-etäisyyttä, joka siis huomioi luokkaellipsien kiertymisen piirreavaruudessa. Alla olevassa kuvassa esiintyvät luokan jakauman muotoa kuvastavan ellipsin kaksi pistettä ovat yhtä etäällä luokan keskipisteestä tämän metriikan mukaan! x 2 x 1
 i Päätöspinnat ovat siis jälleen hypertasoja, mutta nyt tasot eivät ole yleisesti ottaen kohtisuorassa luokkien keskipisteitä yhdistäviä janoja")
21 33 / 99 Vastaavalla tavalla kuin edellisessä kappaleessa diskriminanttifunktiosta voidaan jättää pois luokasta riippumattomia termejä ja muuntaa se lineaariseen muotoon:, jossa t g i ( x) w ix + wi0 w i Σ 1 1 t 1 m i ja w i0 -- m 2 iσ mi + ln P ( ω ) i Päätöspinnat ovat siis jälleen hypertasoja, mutta nyt tasot eivät ole yleisesti ottaen kohtisuorassa luokkien keskipisteitä yhdistäviä janoja vastaan. Tasojen yhtälöt voidaan johtaa vastaavalla tavalla kuin edellä.
22 34 / Tapaus Σ i mielivaltainen Kullakin luokalla on mielivaltainen kovarianssimatriisi, joten alkuperäisestä diskriminanttifunktiosta voidaan pudottaa pois vain termi (d/2)ln 2π. Pienen manipulaation jälkeen saadaan kvadraattinen (neliöllinen) muoto:, jossa g i ( x) x t t W i x + w ix + wi t 1 W i --Σ 2 i, wi Σ i mi ja w i m 2 iσi mi -- ln Σ 2 i + ln P( ω i ) Kaksiluokkaisessa ongelmassa päätöspinnat ovat hyperkvadreja (hyperquadrics): hypertasot hypertasoparit hyperpallot hyperellipsoidit hyperparaboloidit hyperhyperboloidit Jopa 1-ulotteisessa tapauksessa päätösalueet saattavat jakaantua moneen osaan: Seuraavilla sivuilla on esitetty lisää esimerkkejä päätöspinnoista.
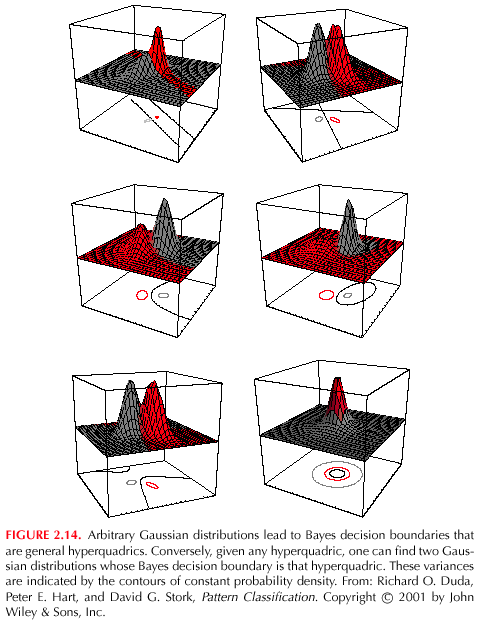
23 35 / 99
24 36 / 99
25 37 / 99 Allaolevassa kuvassa pyritään erottelemaan neljä Gaussista luokkaa toisistaan: Luokittelija tekee päätöksen jakaumien muodot huomioiden. Alla olevassa kuvassa keskellä oleva piste x kuuluu luokkaan ω 2, vaikka se on lähempänä luokan ω 1 keskipistettä! Minimietäisyysluokittelija sijoittaisi hahmon siis luokkaan ω 1. x 2 ω 1 ω 2 x 1
26 38 / Virheen todennäköisyydestä Tarkastellaan kaksiluokkaista tapausta, jossa luokittelijalle on opetettu päätöspinta. Koska luokkajakaumat ovat yleensä osittain päällekkäiset, tapahtuu ajoittain luokitteluvirhe: piirrevektori x kuuluu päätösalueeseen R 1, vaikka hahmo kuuluu luokkaan ω 2 piirrevektori x kuuluu päätösalueeseen R 2, vaikka hahmo kuuluu luokkaan ω 1 Virheen todennäköisyys saadaan seuraavasti: P( virhe) P( x R 2, ω 1 ) + P( x R 1, ω 2 ) P( x R 2 ω 1 )P( ω 1 ) + P( x R 1 ω 2 )P( ω 2 ) p ( x ω )P( ω ) dx 1 + p( x ω 1 2 )P( ω 2 ) dx R 2 R 1 Tulosta havainnollistetaan seuraavassa kuvassa. Päätöspinta on tässä pelkkä kynnys x* ja se on selvästi asetettu epäoptimaaliseen kohtaan; Bayesin valinta on x B. Kuvankin mukaan Bayesin päätössääntö johtaa pienimpään luokitteluvirheeseen, koska virhettä edustava pinta-ala on pienin mahdollinen.
27 39 / 99 Moniluokkaisessa tapauksessa on helpompaa laskea oikean luokittelun todennäköisyys: c P( oikein) P( x R i, ω i ) i 1 c i 1 c i 1 P( x R i ω i ) P ( ω i ) R i p( x ω i )P( ω i ) dx Bayesin luokittelija maksimoi tämän todennäköisyyden valitsemalla päätösalueet siten, että integroitava lauseke on suurin mahdollinen kaikilla x. Tämän johdosta virheen todennäköisyys on pienin mahdollinen: P(virhe)1-P(oikein).
28 40 / Spesifisyys, sensitiivisyys, testin ennustearvo, ROC-käyrät Kaksiluokkaisessa ongelmassa on usein hyödyllistä tarkastella spesifisyyttä ja sensitiivisyyttä, jotka kuvastavat luokittelijan kykyä erotella luokat toisistaan. Tarkastellaan esimerkkinä hiihtäjien doping-testausta, jossa tavoitteena on erottaa dopingia käyttäneet. Seuraava nelikenttä kuvastaa minkä verran hiihtäjiä luokittelija on luokitellut oikein ja väärin: Test positive Test negative Doping present True positives False negatives Doping absent False positives True negatives Sensitiivisyys: Sensitivity True positives True positives + False negatives Spesifisyys: Specificity True negatives True negatives + False positives Positiivisen testin ennustearvo: Predictive value of positive test True positives True positives + False positives Negatiivisen testin ennustearvo: Predictive value of negative test True negatives True negatives + False negatives
29 41 / 99 Voidaan käyttää myös seuraavia nimikkeitä kentille: oikea hälytys (hit): true positives, TP väärä hälytys (false alarm): false positives, FP väärä hylkäys (miss): false negatives, FN oikea hylkäys (correct rejection): true negatives, TN Tarkastellaan tilannetta, jossa käytetään vain yhtä piirrettä. Oletetaan, että jakaumat ovat osittain päällekkäiset kuten kuvassa (esittää tutkapulssin ilmaisemista vastaanotetun signaalin amplitudimittauksella): TN TP FN FP Kuvaan on piirretty päälle edellä esitetyn nelikentän mukaiset merkinnät (TP, FP, TN, FN), joille on näin saatu geometriset tulkinnat. Kun kynnysarvo x* (päätöspinta) on kiinnitetty, sensitiivisyys ja spesifisyys saadaan laskettua helposti luokittelutuloksista kun tapausten luokat tunnetaan. Luokkien erottuvuuden mittana voidaan käyttää suuretta: d' µ 2 µ σ, joka ilmaisee Gaussisesti jakautuneiden luokkien keskipisteiden välisen etäisyyden (yhteisen) keskihajonnan monikertana. Mitä suurempi d on, sitä paremmin luokat erottuvat toisistaan ja luokittelija suoriutuu hyvällä suorituskyvyllä.
30 42 / 99 Jos oletetaan tietyllä etäisyydellä d sijaitsevat jakaumat ja muutellaan luokittelijan kynnysarvoa x* systemaattisesti, saadaan jokaisella asetuksella (aineisto läpiajamalla) yksi sensitiivisyys-spesifisyys-lukupari. Nämä lukuparit voidaan esittää koordinaattipisteinä koordinaatistossa, jossa vaaka-akselina on väärien hälytysten todennäköisyys (1-Spesifisyys) ja pystyakselina oikean hälytyksen todennäköisyys (Sensitiivisyys): Sensitiivisyys 1-Spesifisyys Jokaisella d -suureen arvolla saadaan erillinen käyrä, ROC-käyrä. Jos d 0, jakaumat ovat täysin päällekkäisiä ja erottuvuus huonoin. Erottuvuus on sitä parempi, mitä lähempää käyrä menee vasenta ylänurkkaa. Tutkaesimerkissämme valittu x*- kynnysarvo on johtanut osumaan täplän osoittamaan kohtaan. Vaihtelemalla kynnysarvoa, täplä liikkuisi pitkin käyrää d 3.
31 43 / 99 Kuvasta tehdään tärkeä havainto: Jakaumien ollessa kiinnitetyt, kun sensitiivisyys kasvaa suureksi niin spesifisyys pienenee huomattavasti, ja päinvastoin. Mitä tämä tarkoittaa tutkasignaalin ilmaisussa? Jakaumien ollessa monimutkaiset ROC-käyrä on monimutkaisempi: 2.8. Bayesin päätösteoria diskreeteille muuttujille Useissa sovelluksissa piirteet ovat kokonaislukumuuttujia, jotka voivat saada arvot v 1,...,v m. Todennäköisyystiheysfunktioista tulee singulaarisia ja integraalimerkinnät joudutaan vaihtamaan summamerkintöihin. Esimerkiksi Bayesin kaava saa muodon: P( ω j x) P( x ω j )P( ω j ) P( x) P( x ω j )P( ω j ) c i 1 P( x ω i )P( ω i ) Ehdollisen riskin määritelmä ei muutu, joten toiminnon α valinta saadaan kaavasta:
32 44 / 99 α* arg min R( ω i x) i Suurimpaan posterioritodennäköisyyteen perustuvan päätössäännön muoto ei myöskään muutu, eikä aiemmin esiteltyjen diskriminanttifunktioiden muodot Bayesin verkot Kaikissa sovelluksissa tietämyksemme ratkaistavasta ongelmasta ei sisällä tietoa piirteiden jakaumista, vaan osassa tiedetään jotain piirteiden välisistä riippuvuuksista tai riippumattomuuksista. Bayesin verkot (Bayesian networks) on kehitetty mallintamaan tällaista tietoa ja tekemään sen perusteella tilastollista päättelyä. Muita nimikkeitä ovat Bayesin uskomusverkot (Bayesian belief networks), kausaaliverkot (causal neworks) ja uskomusverkot (belief networks). Mikäli kahdelle satunnaismuuttujalle x ja y pätee: p(x, y) p(x)p(y), näiden muuttujien sanotaan olevan tilastollisesti riippumattomia. Samoin jonkin piirrevektorin komponentit voivat olla tilastollisesti riippumattomia. Alla olevassa kuvassa on esitetty 3-ulotteisten piirrevektorien avulla erään luokan sijoittuminen piirreavaruuteen. Muuttujat x 1 ja x 3 ovat toisistaan tilastollisesti riippumattomia, mutta muut eivät. Mistä tämä nähdään? Bayesin verkot ovat suunnattuja syklittömiä verkkoja, joka sisältää solmuja ja niitä yhdistäviä suunnattuja linkkejä. Linkit esittävät muuttujien välisiä riippuvuussuhteita, kuten syy-seuraus-suhteita. Verkot voivat toimia myös moniulotteisten jatkuvien jakaumien esitystapana, mutta käytännössä niitä on eniten sovellettu diskreettien todennäköisyysmassojen esittämiseen. Kukin solmu A, B,... esittää yhtä ongelman muuttujaa. Kullakin diskreetillä muuttujalla voi olla useita eri tiloja, joita merkitään pienellä kirjaimella vastaavasti a i, b j,... alaindeksin merkitessä tiettyä tilaa. Esimerkiksi A voi merkitä binäärisen kytkimen tilaa: a 1 on ja a 2 off, jolloin vaikkapa P(a 1 )0,739 ja P(a 2 )0,261. Todennäköisyydet summautuvat ykköseksi kaikissa muuttujissa. Alla olevassa kuvassa solmusta A solmuun C kulkeva linkki esittää ehdollisia todennäköisyyksiä P( c i a j ), joka tiiviimmin ilmaistaan muodossa P( c a), jossa a ja c ovat muuttujien A ja C tilat koottuina vektoreiksi: a [ a 1,, a n ] T ja c [ c 1,, c m ] T.
33 45 / 99 Bayesin päättelyn avulla voidaan verkkoa hyödyntäen laskea kunkin muuttujan eri arvojen todennäköisyydet. Itse asiassa, mikä tahansa useasta muuttujasta koostuvan yhdistelmän todennäköisyys (yhteistodennäköisyys, joint probability) on mahdollista laskea verkosta. Todennäköisyyksien laskennassa huomioidaan verkon ilmoittamat riippuvuudet, jolloin päästään yksinkertaistamaan (ja nopeuttamaan) laskentaa merkittävästi. Tarkastellaan ensin yksittäisen muuttujan arvojen todennnäköisyyksien laskemista esimerkkien avulla. Ennen esimerkkejä kolme tärkeää seikkaa: 1) Marginalisointi, jossa todennäköisyyksiä summataan määrättyjen muuttujien
34 46 / 99 P(a) P(b a) P(c b) P(d c) P(e) E A B C D P(f e) F G P(g e) kaikkien vaihtoehtojen ylitse. Alla esiintyvissä merkinnöissä esiintyy kaksin- ja kolminkertaisia summauslausekkeita, esimerkiksi: 2) Bayesin kaava, eli: H P(h f,g) Figure Vasemmalla lineaarinen ketju, oikealla silmukka. a, b, c P( a, b, c) a P( a, b) P( a)p( b a) b c P( a, b, c)
35 47 / 99 3) Vakiotermien siirtäminen summalausekkeen vasemmalle puolelle nopeuttaa laskentaa. Seuraavaksi havainnollistetaan verkon muuttujien todennäköisyyksien laskemista. Vasemman puoleiselle verkolle voidaan laskea esimerkiksi P(d): a, b, c c P( d) P( a, b, c, d) a, b, c a, b, c P( a)p( b, c, d a) a, b, c P( a)p b a P( a)p b a a, b, c ( )P( c, d a, b) ( )P( c a, b)p( d a, b, c) P( a)p( b a)p( c b)p( d c) P( d c) P( c b) P( b a)p( a) b a Huomaa, että viimeisellä rivillä kyseessä on sisäkkäiset silmukat. Entä kuinka lasketaan P(b) samalle verkolle? Aivan vastaavalla tavalla: Vastaavasti oikeanpuoleiselle silmukkarakenteelle voidaan laskea esimerkiksi P(h): Entä kuinka lasketaan P(g) samalle verkolle? Edellä olevissa lausekkeissa viimeisen muodon johtaminen edelliseltä riviltä vaikuttaa vain laskennan määrään.
36 48 / 99 a, c, d c a P( b) P( a, b, c, d) a, c, d a, c, d P( a)p( b, c, d a) a, c, d P( a)p b a P( a)p b a a, c, d P( c b) ( )P( c, d a, b) ( )P( c a, b)p( d a, b, c) P( a)p( b a)p( c b)p( d c) d P( b a)p( a) P( d c) P( b a)p( a) c a P( c b) d P( d c) Edellä laskettiin tiettyjien muuttujien arvojen todennäköisyyksiä, kun verkon muiden muuttujien arvoja ei tunnettu. Tällöin laskelmissa tuli käydä kaikki mahdolliset muuttujien arvot läpi ja laskea näiden vaihtoehtojen todennäköisyyksillä painotettu tulos. Seuraavaksi havainnollistetaan Bayesin verkon käyttämistä tiettyjen muuttujien posteriotodennäköisyyksien laskemisessa, kun eräiden muuttujien arvot tunnetaan. Käytännön sovelluksissa muuttujien arvot saadaan esimerkiksi muista sovelluksista syötteinä tai vaikkapa mittaamalla ohjattavan toimilaitteen sensoreilla. Tätä ulkoista informaatiota voidaan kutsua todisteaineistoksi (evidence) toimintaympäristön tilasta. Merkitään muuttujajoukon X a posteriori todennäköisyyttä symbolilla P( X e). Muuttuja e merkitsee muuttujajoukkoon X muista verkon osista saatavaa todistu-
37 49 / 99 e, f, g P( h) P( e, f, g, h) e, f, g e, f, g f, g e, f, g P( e)p( f, g, h e) e, f, g P( e)p f e P( e)p f e ( )P( g, h e, f) ( )P( g e, f)p( h e, f, g) P( e)p( f e)p g e P( h f, g) e ( )P( h f, g) P( e)p( f e)p( g e) saineistoa siitä missä tilassa X on. Voidaankin määritellä, että uskomus (belief) tarkoittaa ehdollista todennäköisyyttä P( X e) että muuttujajoukko X on tietyssä tilassa, kun verkon sisältämä todennäköisyystieto tunnetaan. Ajatuksena on hyödyntää päättelyssä ulkoisen informaation lisäksi kaikki verkon sisältämä todennäköisyystieto linkkien esittämän riippuvuustiedon mukaisesti minkä tahansa muuttujan posteriorien laskemiseksi. Tyypillisesti halutaan laskea tietyn muuttujan todennäköisin tila; esimerkiksi onko saaliskala todennäköisemmin lohi vai meriahven, kun vuodenaika, kalastuspaikkakunta ja muita mittaustietoja on käytettävissä. Oleellisessa roolissa on Bayesin kaavasta saatava lauseke: P( X e) P( X, e) P( e) αp ( X, e ) Tämä posterioritodennäköisyyden lauseke lasketaan jokaiselle muuttujan X tilalle erikseen, minkä jälkeen suurin todennäköisyysarvo määrää todennäköisimmän
38 50 / 99 e, f, h P( g) P( e, f, g, h) e, f, h e, f, h f, h e, f, h P( e)p( f, g, h e) e, f, h P( e)p f e P( e)p f e ( )P( g, h e, f) ( )P( g e, f)p( h e, f, g) P( e)p( f e)p g e P( h f, g) e ( )P( h f, g) P( e)p( f e)p( g e) tilan. Termiä α voidaan laskea aivan lopuksi; lausekkeen käyttöä havainnollistetaan seuraavaksi. Esimerkki: Kalalajin päätteleminen Bayesin verkon avulla Kuvatkoon alla esitetty kaavio käytettävää Bayesin verkkoa: Seuraavat taulukot kuvaavat asiantuntijan asettamia todennäköisyyksiä:
39 51 / 99 a 1 talvi a 2 kevät a 3 kesä a 4 syksy c 1 kirkas c 2 keskink. c 3 tumma P(a) A aika B paikka P(x a) P(x b) X laji P(c x) P(d x) C kirkkaus P(b) D pituus b 1 Pohjois-Atlantti b 2 Etelä-Atlantti x 1 lohi x 2 meriahven d 1 pitkä d 2 lyhyt P(a i ) 0,25 0,25 0,25 0,25 P(b i ) 0,6 0,4 P(c i x 1 ) 0,6 0,2 0,2 P(c i x 2 ) 0,2 0,3 0,5 P(d i x 1 ) 0,3 0,7 P(d i x 2 ) 0,6 0,4 i,j P(x 1 a i,b j ) P(x 2 a i,b j ) 1,1 0,5 0,5 1,2 0,7 0,3 2,1 0,6 0,4 2,2 0,8 0,2 3,1 0,4 0,6 3,2 0,1 0,9 4,1 0,2 0,8 4,2 0,3 0,7 Käytetään nyt esiteltyä Bayesin verkkoa päättelemään kalalaji. (Päätelmiä voitaisiin tehdä mistä tahansa muustakin verkon muuttujasta.) Kirjoitetaan ensin verkon
40 52 / 99 muuttujien tilastollisten riippuvuuksien mukainen yhteistodennäköisyyden lauseke: P( a, b, x, c, d) P( a)p( b a)p( x a, b)p( c a, b, x)p( d a, b, x, c) Kerätään todistusaineistoa kullekin muuttujalle olettaen että muuttujat ovat tilastollisesti riippumattomia: kala on väriltään vaalea (c 1 ) kala on saalistettu Etelä-Atlantilta (b 2 ) ei tiedetä mihin vuodenaikaan kala on saatu pituustietoa ei ole käytettävissä. Millä todennäköisyydellä kala on lohi? P( a)p( b)p( x a, b)p( c x)p( d x) P( x 1 c 1, b 2 ) P ( x 1, c 1, b 2 ) P( c 1, b 2 ) αp ( x, c, b ) α a, d α a, d P( x 1, a, b 2, c 1, d) P( a)p( b 2 )P( x 1 a, b 2 )P( c 1 x 1 )P( d x 1 ) αp( b 2 )P( c 1 x 1 ) P( a)p( x 1 a, b 2 ) a α( 0, 114) d P( d x 1 ) Millä todennäköisyydellä kala on meriahven? P( x 2 c 1, b 2 ) P ( x 2, c 1, b 2 ) P( c 1, b 2 ) αp ( x, c, b ) α( 0, 066) Kala on joko lohi tai meriahven, joten posteriorit summautuvat arvoon 1. Tästä
41 53 / 99 saadaan, että α1/0,18, P(x 1 c 1,b 2 )0,63 ja P(x 2 c 1,b 2 )0,27. Saaliskala on siis todennäköisemmin lohi! Esimerkki loppuu. Mikäli ei tiedetä mitään ongelmaa kuvaavien muuttujien tilastollisista riippuvuuksista, voidaan käyttää esimerkiksi Naiivia Bayesin verkkoa (Naive Bayes network). Tällöin muuttujat oletetaan ehdollisesti riippumattomiksi ja verkon rakenne on erityisen yksinkertainen: X A B C D Kuvassa juurimuuttuja (solmu) X on muuttuja, jonka suhteen tilastollisen riippumattomuuden oletus tehdään. X voi olla esimerkiksi luokkamuuttuja, jonka avulla (A/B/C/D)-muuttujien edustama hahmo pyritään tunnistamaan. Päättely perustuu posterioritodennäköisyyksien laskentaan kuten edellä. P( x a, b, c, d) αp( x)p( a x)p( b x)p( c x)p( d x) Mikäli riippumattomuusoletus pitää paikkansa sovelluksessa, kyseessä on minimivirheluokittelija. Naiivia Bayes-verkkoa on käytetty suurella menestyksellä monissa käytännön sovelluksissa. Toinen vaihtoehto on käyttää algoritmeja, jotka pyrkivät rakentamaan verkon automaattisesti opetusaineiston perusteella tarkastelemalla muuttujien välisiä riippuvuuksia.
SGN-2500 Johdatus hahmontunnistukseen 2007 Luennot 4 ja 5
 SGN-2500 Johdatus hahmontunnistukseen 2007 Luennot 4 ja 5 Jussi Tohka jussi.tohka@tut.fi Signaalinkäsittelyn laitos Tampereen teknillinen yliopisto SGN-2500 Johdatus hahmontunnistukseen 2007Luennot 4 ja
SGN-2500 Johdatus hahmontunnistukseen 2007 Luennot 4 ja 5 Jussi Tohka jussi.tohka@tut.fi Signaalinkäsittelyn laitos Tampereen teknillinen yliopisto SGN-2500 Johdatus hahmontunnistukseen 2007Luennot 4 ja
1. TILASTOLLINEN HAHMONTUNNISTUS
 1. TILASTOLLINEN HAHMONTUNNISTUS Tilastollisissa hahmontunnistusmenetelmissä piirteitä tarkastellaan tilastollisina muuttujina Luokittelussa käytetään hyväksi seuraavia tietoja: luokkien a priori tn:iä,
1. TILASTOLLINEN HAHMONTUNNISTUS Tilastollisissa hahmontunnistusmenetelmissä piirteitä tarkastellaan tilastollisina muuttujina Luokittelussa käytetään hyväksi seuraavia tietoja: luokkien a priori tn:iä,
Moniulotteisia todennäköisyysjakaumia
 Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (007) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (007) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia
 Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (006) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (006) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
805306A Johdatus monimuuttujamenetelmiin, 5 op
 monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Lineaarinen erotteluanalyysi (LDA, Linear discriminant analysis) Erotteluanalyysin avulla pyritään muodostamaan selittävistä muuttujista
monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Lineaarinen erotteluanalyysi (LDA, Linear discriminant analysis) Erotteluanalyysin avulla pyritään muodostamaan selittävistä muuttujista
805306A Johdatus monimuuttujamenetelmiin, 5 op
 monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Lineaarinen erotteluanalyysi (LDA, Linear discriminant analysis) Erotteluanalyysin avulla pyritään muodostamaan selittävistä muuttujista
monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Lineaarinen erotteluanalyysi (LDA, Linear discriminant analysis) Erotteluanalyysin avulla pyritään muodostamaan selittävistä muuttujista
Inversio-ongelmien laskennallinen peruskurssi Luento 7
 Inversio-ongelmien laskennallinen peruskurssi Luento 7 Kevät 2012 1 Tilastolliset inversio-ongelmat Tilastollinen ionversio perustuu seuraaviin periaatteisiin: 1. Kaikki mallissa olevat muuttujat mallinnetaan
Inversio-ongelmien laskennallinen peruskurssi Luento 7 Kevät 2012 1 Tilastolliset inversio-ongelmat Tilastollinen ionversio perustuu seuraaviin periaatteisiin: 1. Kaikki mallissa olevat muuttujat mallinnetaan
Kaksiluokkainen tapaus, lineaarinen päätöspinta, lineaarisesti erottuvat luokat
 1 Tukivektoriluokittelija Tukivektorikoneeseen (support vector machine) perustuva luoikittelija on tilastollisen koneoppimisen teoriaan perustuva lineaarinen luokittelija. Perusajatus on sovittaa kahden
1 Tukivektoriluokittelija Tukivektorikoneeseen (support vector machine) perustuva luoikittelija on tilastollisen koneoppimisen teoriaan perustuva lineaarinen luokittelija. Perusajatus on sovittaa kahden
Moniulotteisia todennäköisyysjakaumia. Moniulotteisia todennäköisyysjakaumia. Moniulotteisia todennäköisyysjakaumia: Mitä opimme?
 TKK (c) Ilkka Mellin (4) Moniulotteisia todennäköisyysjakaumia Johdatus todennäköisyyslaskentaan Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (4) Moniulotteisia todennäköisyysjakaumia: Mitä
TKK (c) Ilkka Mellin (4) Moniulotteisia todennäköisyysjakaumia Johdatus todennäköisyyslaskentaan Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (4) Moniulotteisia todennäköisyysjakaumia: Mitä
Johdatus todennäköisyyslaskentaan Moniulotteisia todennäköisyysjakaumia. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus todennäköisyyslaskentaan Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (005) 1 Moniulotteisia todennäköisyysjakaumia Multinomijakauma Kaksiulotteinen normaalijakauma TKK (c) Ilkka
Johdatus todennäköisyyslaskentaan Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (005) 1 Moniulotteisia todennäköisyysjakaumia Multinomijakauma Kaksiulotteinen normaalijakauma TKK (c) Ilkka
Jatkuvat satunnaismuuttujat
 Jatkuvat satunnaismuuttujat Satunnaismuuttuja on jatkuva jos se voi ainakin periaatteessa saada kaikkia mahdollisia reaalilukuarvoja ainakin tietyltä väliltä. Täytyy ymmärtää, että tällä ei ole mitään
Jatkuvat satunnaismuuttujat Satunnaismuuttuja on jatkuva jos se voi ainakin periaatteessa saada kaikkia mahdollisia reaalilukuarvoja ainakin tietyltä väliltä. Täytyy ymmärtää, että tällä ei ole mitään
Todennäköisyyden ominaisuuksia
 Todennäköisyyden ominaisuuksia 0 P(A) 1 (1) P(S) = 1 (2) A B = P(A B) = P(A) + P(B) (3) P(A) = 1 P(A) (4) P(A B) = P(A) + P(B) P(A B) (5) Tapahtuman todennäköisyys S = {e 1,..., e N }. N A = A. Kun alkeistapaukset
Todennäköisyyden ominaisuuksia 0 P(A) 1 (1) P(S) = 1 (2) A B = P(A B) = P(A) + P(B) (3) P(A) = 1 P(A) (4) P(A B) = P(A) + P(B) P(A B) (5) Tapahtuman todennäköisyys S = {e 1,..., e N }. N A = A. Kun alkeistapaukset
3.7 Todennäköisyysjakaumia
 MAB5: Todennäköisyyden lähtökohdat 4 Luvussa 3 Tunnusluvut perehdyimme jo jakauman käsitteeseen yleensä ja normaalijakaumaan vähän tarkemmin. Lähdetään nyt tutustumaan binomijakaumaan ja otetaan sen jälkeen
MAB5: Todennäköisyyden lähtökohdat 4 Luvussa 3 Tunnusluvut perehdyimme jo jakauman käsitteeseen yleensä ja normaalijakaumaan vähän tarkemmin. Lähdetään nyt tutustumaan binomijakaumaan ja otetaan sen jälkeen
4.0.2 Kuinka hyvä ennuste on?
 Luonteva ennuste on käyttää yhtälöä (4.0.1), jolloin estimaattori on muotoa X t = c + φ 1 X t 1 + + φ p X t p ja estimointivirheen varianssi on σ 2. X t }{{} todellinen arvo Xt }{{} esimaattori = ε t Esimerkki
Luonteva ennuste on käyttää yhtälöä (4.0.1), jolloin estimaattori on muotoa X t = c + φ 1 X t 1 + + φ p X t p ja estimointivirheen varianssi on σ 2. X t }{{} todellinen arvo Xt }{{} esimaattori = ε t Esimerkki
P (X B) = f X (x)dx. xf X (x)dx. g(x)f X (x)dx.
 = f X (x)dx. xf X (x)dx. g(x)f X (x)dx.") Yhteenveto: Satunnaisvektorit ovat kuvauksia tn-avaruudelta seillaiselle avaruudelle, johon sisältyy satunnaisvektorin kaikki mahdolliset reaalisaatiot. Satunnaisvektorin realisaatio eli otos on jokin
Yhteenveto: Satunnaisvektorit ovat kuvauksia tn-avaruudelta seillaiselle avaruudelle, johon sisältyy satunnaisvektorin kaikki mahdolliset reaalisaatiot. Satunnaisvektorin realisaatio eli otos on jokin
1. TODENNÄKÖISYYSJAKAUMIEN ESTIMOINTI
 1. TODENNÄKÖISYYSJAKAUMIEN ESTIMOINTI Edellä esitelty Bayesiläinen luokittelusääntö ( Bayes Decision Theory ) on optimaalinen tapa suorittaa luokittelu, kun luokkien tnjakaumat tunnetaan Käytännössä tnjakaumia
1. TODENNÄKÖISYYSJAKAUMIEN ESTIMOINTI Edellä esitelty Bayesiläinen luokittelusääntö ( Bayes Decision Theory ) on optimaalinen tapa suorittaa luokittelu, kun luokkien tnjakaumat tunnetaan Käytännössä tnjakaumia
1. TODENNÄKÖISYYSJAKAUMIEN ESTIMOINTI
 1. TODENNÄKÖISYYSJAKAUMIEN ESTIMOINTI Edellä esitelty Bayesiläinen luokittelusääntö ( Bayes Decision Theory ) on optimaalinen tapa suorittaa luokittelu, kun luokkien tnjakaumat tunnetaan Käytännössä tnjakaumia
1. TODENNÄKÖISYYSJAKAUMIEN ESTIMOINTI Edellä esitelty Bayesiläinen luokittelusääntö ( Bayes Decision Theory ) on optimaalinen tapa suorittaa luokittelu, kun luokkien tnjakaumat tunnetaan Käytännössä tnjakaumia
Mallipohjainen klusterointi
 Mallipohjainen klusterointi Marko Salmenkivi Johdatus koneoppimiseen, syksy 2008 Luentorunko perjantaille 5.12.2008 Johdattelua mallipohjaiseen klusterointiin, erityisesti gaussisiin sekoitemalleihin Uskottavuusfunktio
Mallipohjainen klusterointi Marko Salmenkivi Johdatus koneoppimiseen, syksy 2008 Luentorunko perjantaille 5.12.2008 Johdattelua mallipohjaiseen klusterointiin, erityisesti gaussisiin sekoitemalleihin Uskottavuusfunktio
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 3. marraskuuta 2007 Antti Rasila () TodB 3. marraskuuta 2007 1 / 18 1 Varianssin luottamusväli, jatkoa 2 Bernoulli-jakauman odotusarvon luottamusväli 3
Sovellettu todennäköisyyslaskenta B Antti Rasila 3. marraskuuta 2007 Antti Rasila () TodB 3. marraskuuta 2007 1 / 18 1 Varianssin luottamusväli, jatkoa 2 Bernoulli-jakauman odotusarvon luottamusväli 3
1. Jatketaan luentojen esimerkkiä 8.3. Oletetaan kuten esimerkissä X Y Bin(Y, θ) Y Poi(λ) λ y. f X (x) (λθ)x
 Y Poi(λ) λ y. f X (x) (λθ)x") HY, MTL / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIb, syksy 017 Harjoitus 5 Ratkaisuehdotuksia Tehtäväsarja I 1. Jatketaan luentojen esimerkkiä 8.3. Oletetaan kuten esimerkissä X
HY, MTL / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIb, syksy 017 Harjoitus 5 Ratkaisuehdotuksia Tehtäväsarja I 1. Jatketaan luentojen esimerkkiä 8.3. Oletetaan kuten esimerkissä X
Tilastollinen testaus. Vilkkumaa / Kuusinen 1
 Tilastollinen testaus Vilkkumaa / Kuusinen 1 Motivointi Viime luennolla: havainnot generoineen jakauman muoto on usein tunnettu, mutta parametrit tulee estimoida Joskus parametreista on perusteltua esittää
Tilastollinen testaus Vilkkumaa / Kuusinen 1 Motivointi Viime luennolla: havainnot generoineen jakauman muoto on usein tunnettu, mutta parametrit tulee estimoida Joskus parametreista on perusteltua esittää
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 5B Bayesläiset piste- ja väliestimaatit Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 5B Bayesläiset piste- ja väliestimaatit Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto
P(X = x T (X ) = t, θ) = p(x = x T (X ) = t) ei riipu tuntemattomasta θ:sta. Silloin uskottavuusfunktio faktorisoituu
 = t, θ) = p(x = x T (X ) = t) ei riipu tuntemattomasta θ:sta. Silloin uskottavuusfunktio faktorisoituu") 1. Tyhjentävä tunnusluku (sucient statistics ) Olkoon (P(X = x θ) : θ Θ) todennäköisyysmalli havainnolle X. Datan funktio T (X ) on Tyhjentävä tunnusluku jos ehdollinen todennäköisyys (ehdollinen tiheysfunktio)
1. Tyhjentävä tunnusluku (sucient statistics ) Olkoon (P(X = x θ) : θ Θ) todennäköisyysmalli havainnolle X. Datan funktio T (X ) on Tyhjentävä tunnusluku jos ehdollinen todennäköisyys (ehdollinen tiheysfunktio)
Lineaariset luokittelumallit: regressio ja erotteluanalyysi
 Lineaariset luokittelumallit: regressio ja erotteluanalyysi Aira Hast Johdanto Tarkastellaan menetelmiä, joissa luokittelu tehdään lineaaristen menetelmien avulla. Avaruus jaetaan päätösrajojen avulla
Lineaariset luokittelumallit: regressio ja erotteluanalyysi Aira Hast Johdanto Tarkastellaan menetelmiä, joissa luokittelu tehdään lineaaristen menetelmien avulla. Avaruus jaetaan päätösrajojen avulla
Inversio-ongelmien laskennallinen peruskurssi Luento 2
 Inversio-ongelmien laskennallinen peruskurssi Luento 2 Kevät 2012 1 Lineaarinen inversio-ongelma Määritelmä 1.1. Yleinen (reaaliarvoinen) lineaarinen inversio-ongelma voidaan esittää muodossa m = Ax +
Inversio-ongelmien laskennallinen peruskurssi Luento 2 Kevät 2012 1 Lineaarinen inversio-ongelma Määritelmä 1.1. Yleinen (reaaliarvoinen) lineaarinen inversio-ongelma voidaan esittää muodossa m = Ax +
Todennäköisyyslaskennan ja tilastotieteen peruskurssi Esimerkkikokoelma 3
 Todennäköisyyslaskennan ja tilastotieteen peruskurssi Esimerkkikokoelma 3 Aiheet: Satunnaisvektorit ja moniulotteiset jakaumat Tilastollinen riippuvuus ja lineaarinen korrelaatio Satunnaisvektorit ja moniulotteiset
Todennäköisyyslaskennan ja tilastotieteen peruskurssi Esimerkkikokoelma 3 Aiheet: Satunnaisvektorit ja moniulotteiset jakaumat Tilastollinen riippuvuus ja lineaarinen korrelaatio Satunnaisvektorit ja moniulotteiset
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 4B Bayesläinen tilastollinen päättely Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 4B Bayesläinen tilastollinen päättely Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy
Johdatus todennäköisyyslaskentaan Normaalijakaumasta johdettuja jakaumia. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus todennäköisyyslaskentaan Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2005) 1 Normaalijakaumasta johdettuja jakaumia Johdanto χ 2 -jakauma F-jakauma t-jakauma TKK (c) Ilkka Mellin
Johdatus todennäköisyyslaskentaan Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2005) 1 Normaalijakaumasta johdettuja jakaumia Johdanto χ 2 -jakauma F-jakauma t-jakauma TKK (c) Ilkka Mellin
1. LINEAARISET LUOKITTIMET
 1. LINEAARISET LUOKITTIMET Edellisillä luennoilla tarkasteltiin luokitteluongelmaa tnjakaumien avulla ja esiteltiin menetelmiä, miten tarvittavat tnjakaumat voidaan estimoida. Tavoitteena oli löytää päätössääntö,
1. LINEAARISET LUOKITTIMET Edellisillä luennoilla tarkasteltiin luokitteluongelmaa tnjakaumien avulla ja esiteltiin menetelmiä, miten tarvittavat tnjakaumat voidaan estimoida. Tavoitteena oli löytää päätössääntö,
2 exp( 2u), kun u > 0 f U (u) = v = 3 + u 3v + uv = u. f V (v) dv = f U (u) du du f V (v) = f U (u) dv = f U (h(v)) h (v) = f U 1 v (1 v) 2
, kun u > 0 f U (u) = v = 3 + u 3v + uv = u. f V (v) dv = f U (u) du du f V (v) = f U (u) dv = f U (h(v)) h (v) = f U 1 v (1 v) 2") HY, MTO / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIa, syksy 208 Harjoitus 4 Ratkaisuehdotuksia Tehtäväsarja I. Satunnaismuuttuja U Exp(2) ja V = U/(3 + U). Laske f V käyttämällä muuttujanvaihtotekniikkaa.
HY, MTO / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIa, syksy 208 Harjoitus 4 Ratkaisuehdotuksia Tehtäväsarja I. Satunnaismuuttuja U Exp(2) ja V = U/(3 + U). Laske f V käyttämällä muuttujanvaihtotekniikkaa.
Oletetaan, että virhetermit eivät korreloi toistensa eikä faktorin f kanssa. Toisin sanoen
 Yhden faktorin malli: n kpl sijoituskohteita, joiden tuotot ovat r i, i =, 2,..., n. Olkoon f satunnaismuuttuja ja oletetaan, että tuotot voidaan selittää yhtälön r i = a i + b i f + e i avulla, missä
Yhden faktorin malli: n kpl sijoituskohteita, joiden tuotot ovat r i, i =, 2,..., n. Olkoon f satunnaismuuttuja ja oletetaan, että tuotot voidaan selittää yhtälön r i = a i + b i f + e i avulla, missä
Moniulotteiset satunnaismuuttujat ja jakaumat
 Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Moniulotteiset satunnaismuuttujat ja jakaumat KE (2014) 1 Moniulotteiset satunnaismuuttujat ja todennäköisyysjakaumat >> Kaksiulotteiset
Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Moniulotteiset satunnaismuuttujat ja jakaumat KE (2014) 1 Moniulotteiset satunnaismuuttujat ja todennäköisyysjakaumat >> Kaksiulotteiset
Väliestimointi (jatkoa) Heliövaara 1
 Heliövaara 1") Väliestimointi (jatkoa) Heliövaara 1 Bernoulli-jakauman odotusarvon luottamusväli 1/2 Olkoon havainnot X 1,..., X n yksinkertainen satunnaisotos Bernoulli-jakaumasta parametrilla p. Eli X Bernoulli(p).
Väliestimointi (jatkoa) Heliövaara 1 Bernoulli-jakauman odotusarvon luottamusväli 1/2 Olkoon havainnot X 1,..., X n yksinkertainen satunnaisotos Bernoulli-jakaumasta parametrilla p. Eli X Bernoulli(p).
x 4 e 2x dx Γ(r) = x r 1 e x dx (1)
 = x r 1 e x dx (1)") HY / Matematiikan ja tilastotieteen laitos Todennäköisyyslaskenta IIA, syksy 217 217 Harjoitus 6 Ratkaisuehdotuksia Tehtäväsarja I 1. Laske numeeriset arvot seuraaville integraaleille: x 4 e 2x dx ja 1
HY / Matematiikan ja tilastotieteen laitos Todennäköisyyslaskenta IIA, syksy 217 217 Harjoitus 6 Ratkaisuehdotuksia Tehtäväsarja I 1. Laske numeeriset arvot seuraaville integraaleille: x 4 e 2x dx ja 1
4.2.2 Uskottavuusfunktio f Y (y 0 X = x)
") Kuva 4.6: Elektroniikassa esiintyvän lämpökohinan periaate. Lämpökohinaa ε mallinnetaan additiivisella häiriöllä y = Mx + ε. 4.2.2 Uskottavuusfunktio f Y (y 0 X = x) Tarkastellaan tilastollista inversio-ongelmaa,
Kuva 4.6: Elektroniikassa esiintyvän lämpökohinan periaate. Lämpökohinaa ε mallinnetaan additiivisella häiriöllä y = Mx + ε. 4.2.2 Uskottavuusfunktio f Y (y 0 X = x) Tarkastellaan tilastollista inversio-ongelmaa,
MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 4A Parametrien estimointi Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy 2016, periodi
MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 4A Parametrien estimointi Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy 2016, periodi
Epäyhtälöt ovat yksi matemaatikon voimakkaimmista
 6 Epäyhtälöitä Epäyhtälöt ovat yksi matemaatikon voimakkaimmista työvälineistä. Yhtälö a = b kertoo sen, että kaksi ehkä näennäisesti erilaista asiaa ovat samoja. Epäyhtälö a b saattaa antaa keinon analysoida
6 Epäyhtälöitä Epäyhtälöt ovat yksi matemaatikon voimakkaimmista työvälineistä. Yhtälö a = b kertoo sen, että kaksi ehkä näennäisesti erilaista asiaa ovat samoja. Epäyhtälö a b saattaa antaa keinon analysoida
Todennäköisyyslaskun kertaus. Vilkkumaa / Kuusinen 1
 Todennäköisyyslaskun kertaus Vilkkumaa / Kuusinen 1 Satunnaismuuttujat ja todennäköisyysjakaumat Vilkkumaa / Kuusinen 2 Motivointi Kokeellisessa tutkimuksessa tutkittaviin ilmiöihin liittyvien havaintojen
Todennäköisyyslaskun kertaus Vilkkumaa / Kuusinen 1 Satunnaismuuttujat ja todennäköisyysjakaumat Vilkkumaa / Kuusinen 2 Motivointi Kokeellisessa tutkimuksessa tutkittaviin ilmiöihin liittyvien havaintojen
1. Tilastollinen malli??
 1. Tilastollinen malli?? https://fi.wikipedia.org/wiki/tilastollinen_malli https://en.wikipedia.org/wiki/statistical_model http://projecteuclid.org/euclid.aos/1035844977 Tilastollinen malli?? Numeerinen
1. Tilastollinen malli?? https://fi.wikipedia.org/wiki/tilastollinen_malli https://en.wikipedia.org/wiki/statistical_model http://projecteuclid.org/euclid.aos/1035844977 Tilastollinen malli?? Numeerinen
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 18. lokakuuta 2007 Antti Rasila () TodB 18. lokakuuta 2007 1 / 19 1 Tilastollinen aineisto 2 Tilastollinen malli Yksinkertainen satunnaisotos 3 Otostunnusluvut
Sovellettu todennäköisyyslaskenta B Antti Rasila 18. lokakuuta 2007 Antti Rasila () TodB 18. lokakuuta 2007 1 / 19 1 Tilastollinen aineisto 2 Tilastollinen malli Yksinkertainen satunnaisotos 3 Otostunnusluvut
Tehtäväsarja I Tehtävät 1-5 perustuvat monisteen kappaleisiin ja tehtävä 6 kappaleeseen 2.8.
 HY, MTO / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIa, syksy 8 Harjoitus Ratkaisuehdotuksia Tehtäväsarja I Tehtävät -5 perustuvat monisteen kappaleisiin..7 ja tehtävä 6 kappaleeseen.8..
HY, MTO / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIa, syksy 8 Harjoitus Ratkaisuehdotuksia Tehtäväsarja I Tehtävät -5 perustuvat monisteen kappaleisiin..7 ja tehtävä 6 kappaleeseen.8..
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 30. lokakuuta 2007 Antti Rasila () TodB 30. lokakuuta 2007 1 / 23 1 Otos ja otosjakaumat (jatkoa) Frekvenssi ja suhteellinen frekvenssi Frekvenssien odotusarvo
Sovellettu todennäköisyyslaskenta B Antti Rasila 30. lokakuuta 2007 Antti Rasila () TodB 30. lokakuuta 2007 1 / 23 1 Otos ja otosjakaumat (jatkoa) Frekvenssi ja suhteellinen frekvenssi Frekvenssien odotusarvo
BM20A5840 Usean muuttujan funktiot ja sarjat Harjoitus 7, Kevät 2018
 BM20A5840 Usean muuttujan funktiot ja sarjat Harjoitus 7, Kevät 2018 Tehtävä 8 on tällä kertaa pakollinen. Aloittakaapa siitä. 1. Kun tässä tehtävässä sanotaan sopii mahdollisimman hyvin, sillä tarkoitetaan
BM20A5840 Usean muuttujan funktiot ja sarjat Harjoitus 7, Kevät 2018 Tehtävä 8 on tällä kertaa pakollinen. Aloittakaapa siitä. 1. Kun tässä tehtävässä sanotaan sopii mahdollisimman hyvin, sillä tarkoitetaan
Diskreetin satunnaismuuttujan odotusarvo, keskihajonta ja varianssi
 TOD.NÄK JA TILASTOT, MAA0 Diskreetin satunnaismuuttujan odotusarvo, keskihajonta ja varianssi Kuten tilastojakaumia voitiin esittää tunnuslukujen (keskiarvo, moodi, mediaani, jne.) avulla, niin vastaavasti
TOD.NÄK JA TILASTOT, MAA0 Diskreetin satunnaismuuttujan odotusarvo, keskihajonta ja varianssi Kuten tilastojakaumia voitiin esittää tunnuslukujen (keskiarvo, moodi, mediaani, jne.) avulla, niin vastaavasti
Johdatus todennäköisyyslaskentaan Momenttiemäfunktio ja karakteristinen funktio. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus todennäköisyyslaskentaan Momenttiemäfunktio ja karakteristinen funktio TKK (c) Ilkka Mellin (5) 1 Momenttiemäfunktio ja karakteristinen funktio Momenttiemäfunktio Diskreettien jakaumien momenttiemäfunktioita
Johdatus todennäköisyyslaskentaan Momenttiemäfunktio ja karakteristinen funktio TKK (c) Ilkka Mellin (5) 1 Momenttiemäfunktio ja karakteristinen funktio Momenttiemäfunktio Diskreettien jakaumien momenttiemäfunktioita
Mat Sovellettu todennäköisyyslasku A
 TKK / Systeemianalyysin laboratorio Nordlund Mat-.090 Sovellettu todennäköisyyslasku A Harjoitus 7 (vko 44/003) (Aihe: odotusarvon ja varianssin ominaisuuksia, satunnaismuuttujien lineaarikombinaatioita,
TKK / Systeemianalyysin laboratorio Nordlund Mat-.090 Sovellettu todennäköisyyslasku A Harjoitus 7 (vko 44/003) (Aihe: odotusarvon ja varianssin ominaisuuksia, satunnaismuuttujien lineaarikombinaatioita,
Tässä luvussa mietimme, kuinka paljon aineistossa on tarpeellista tietoa Sivuamme kysymyksiä:
 4. Tyhjentyvyys Tässä luvussa mietimme, kuinka paljon aineistossa on tarpeellista tietoa Sivuamme kysymyksiä: Voidaanko päätelmät perustaa johonkin tunnuslukuun t = t(y) koko aineiston y sijasta? Mitä
4. Tyhjentyvyys Tässä luvussa mietimme, kuinka paljon aineistossa on tarpeellista tietoa Sivuamme kysymyksiä: Voidaanko päätelmät perustaa johonkin tunnuslukuun t = t(y) koko aineiston y sijasta? Mitä
30A02000 Tilastotieteen perusteet
 30A02000 Tilastotieteen perusteet Kertaus 1. välikokeeseen Lauri Viitasaari Tieto- ja palvelujohtamisen laitos Kauppatieteiden korkeakoulu Aalto-yliopisto Syksy 2019 Periodi I-II Sisältö Välikokeesta Joukko-oppi
30A02000 Tilastotieteen perusteet Kertaus 1. välikokeeseen Lauri Viitasaari Tieto- ja palvelujohtamisen laitos Kauppatieteiden korkeakoulu Aalto-yliopisto Syksy 2019 Periodi I-II Sisältö Välikokeesta Joukko-oppi
Luento KERTAUSTA Kaksiulotteinen jakauma Pisteparvi, Toyota Avensis -farmariautoja
 1 Luento 23.9.2014 KERTAUSTA Kaksiulotteinen jakauma Pisteparvi, Toyota Avensis -farmariautoja 2 Ristiintaulukko Esim. Toyota Avensis farmariautoja, nelikenttä (2x2-taulukko) 3 Esim. 5.2.6. Markkinointisuunnitelma
1 Luento 23.9.2014 KERTAUSTA Kaksiulotteinen jakauma Pisteparvi, Toyota Avensis -farmariautoja 2 Ristiintaulukko Esim. Toyota Avensis farmariautoja, nelikenttä (2x2-taulukko) 3 Esim. 5.2.6. Markkinointisuunnitelma
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 5A Bayeslainen tilastollinen päättely Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Lukuvuosi
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 5A Bayeslainen tilastollinen päättely Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Lukuvuosi
Yhtälöryhmä matriisimuodossa. MS-A0007 Matriisilaskenta. Tarkastellaan esimerkkinä lineaarista yhtälöparia. 2x1 x 2 = 1 x 1 + x 2 = 5.
 2. MS-A000 Matriisilaskenta 2. Nuutti Hyvönen, c Riikka Kangaslampi Matematiikan ja systeemianalyysin laitos Aalto-yliopisto 2..205 Tarkastellaan esimerkkinä lineaarista yhtälöparia { 2x x 2 = x x 2 =
2. MS-A000 Matriisilaskenta 2. Nuutti Hyvönen, c Riikka Kangaslampi Matematiikan ja systeemianalyysin laitos Aalto-yliopisto 2..205 Tarkastellaan esimerkkinä lineaarista yhtälöparia { 2x x 2 = x x 2 =
Tilastotieteen kertaus. Vilkkumaa / Kuusinen 1
 Tilastotieteen kertaus Vilkkumaa / Kuusinen 1 Motivointi Reaalimaailman ilmiöihin liittyy tyypillisesti satunnaisuutta ja epävarmuutta Ilmiöihin liittyvien havaintojen ajatellaan usein olevan peräisin
Tilastotieteen kertaus Vilkkumaa / Kuusinen 1 Motivointi Reaalimaailman ilmiöihin liittyy tyypillisesti satunnaisuutta ja epävarmuutta Ilmiöihin liittyvien havaintojen ajatellaan usein olevan peräisin
Yhtälöryhmä matriisimuodossa. MS-A0004/A0006 Matriisilaskenta. Tarkastellaan esimerkkinä lineaarista yhtälöparia. 2x1 x 2 = 1 x 1 + x 2 = 5.
 2. MS-A4/A6 Matriisilaskenta 2. Nuutti Hyvönen, c Riikka Kangaslampi Matematiikan ja systeemianalyysin laitos Aalto-yliopisto 5.9.25 Tarkastellaan esimerkkinä lineaarista yhtälöparia { 2x x 2 = x + x 2
2. MS-A4/A6 Matriisilaskenta 2. Nuutti Hyvönen, c Riikka Kangaslampi Matematiikan ja systeemianalyysin laitos Aalto-yliopisto 5.9.25 Tarkastellaan esimerkkinä lineaarista yhtälöparia { 2x x 2 = x + x 2
Osa 2: Otokset, otosjakaumat ja estimointi
 Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi TKK (c) Ilkka Mellin (2007) 1 Estimointi >> Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin
Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi TKK (c) Ilkka Mellin (2007) 1 Estimointi >> Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin
Maximum likelihood-estimointi Alkeet
 Maximum likelihood-estimointi Alkeet Keijo Ruotsalainen Oulun yliopisto, Teknillinen tiedekunta Matematiikan jaos Maximum likelihood-estimointi p.1/20 Maximum Likelihood-estimointi satunnaismuuttujan X
Maximum likelihood-estimointi Alkeet Keijo Ruotsalainen Oulun yliopisto, Teknillinen tiedekunta Matematiikan jaos Maximum likelihood-estimointi p.1/20 Maximum Likelihood-estimointi satunnaismuuttujan X
Käytetään satunnaismuuttujaa samoin kuin tilastotieteen puolella:
 8.1 Satunnaismuuttuja Käytetään satunnaismuuttujaa samoin kuin tilastotieteen puolella: Esim. Nopanheitossa (d6) satunnaismuuttuja X kertoo silmäluvun arvon. a) listaa kaikki satunnaismuuttujan arvot b)
8.1 Satunnaismuuttuja Käytetään satunnaismuuttujaa samoin kuin tilastotieteen puolella: Esim. Nopanheitossa (d6) satunnaismuuttuja X kertoo silmäluvun arvon. a) listaa kaikki satunnaismuuttujan arvot b)
Mat Sovellettu todennäköisyyslasku A. Moniulotteiset jakaumat. Avainsanat:
 Mat-.9 Sovellettu todennäköisyyslasku A Mat-.9 Sovellettu todennäköisyyslasku A / Ratkaisut Aiheet: Avainsanat: Moniulotteiset jakaumat Diskreetti jakauma, Ehdollinen jakauma, Ehdollinen odotusarvo, Jatkuva
Mat-.9 Sovellettu todennäköisyyslasku A Mat-.9 Sovellettu todennäköisyyslasku A / Ratkaisut Aiheet: Avainsanat: Moniulotteiset jakaumat Diskreetti jakauma, Ehdollinen jakauma, Ehdollinen odotusarvo, Jatkuva
Bayesilainen päätöksenteko / Bayesian decision theory
 Bayesilainen päätöksenteko / Bayesian decision theory Todennäköisyysteoria voidaan perustella ilman päätösteoriaa, mutta vasta päätösteorian avulla siitä on oikeasti hyötyä Todennäköisyyteoriassa tavoitteena
Bayesilainen päätöksenteko / Bayesian decision theory Todennäköisyysteoria voidaan perustella ilman päätösteoriaa, mutta vasta päätösteorian avulla siitä on oikeasti hyötyä Todennäköisyyteoriassa tavoitteena
Harjoitus 2: Matlab - Statistical Toolbox
 Harjoitus 2: Matlab - Statistical Toolbox Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen tavoitteet Satunnaismuuttujat ja todennäköisyysjakaumat
Harjoitus 2: Matlab - Statistical Toolbox Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen tavoitteet Satunnaismuuttujat ja todennäköisyysjakaumat
Luento 8: Epälineaarinen optimointi
 Luento 8: Epälineaarinen optimointi Vektoriavaruus R n R n on kaikkien n-jonojen x := (x,..., x n ) joukko. Siis R n := Määritellään nollavektori 0 = (0,..., 0). Reaalisten m n-matriisien joukkoa merkitään
Luento 8: Epälineaarinen optimointi Vektoriavaruus R n R n on kaikkien n-jonojen x := (x,..., x n ) joukko. Siis R n := Määritellään nollavektori 0 = (0,..., 0). Reaalisten m n-matriisien joukkoa merkitään
Lause 4.2. Lineearinen pienimmän keskineliövirheen estimaattoi on lineaarinen projektio.
 Määritelmä 4.3. Estimaattoria X(Y ) nimitetään lineaariseksi projektioksi, jos X on lineaarinen kuvaus ja E[(X X(Y )) Y] 0 }{{} virhetermi Lause 4.2. Lineearinen pienimmän keskineliövirheen estimaattoi
Määritelmä 4.3. Estimaattoria X(Y ) nimitetään lineaariseksi projektioksi, jos X on lineaarinen kuvaus ja E[(X X(Y )) Y] 0 }{{} virhetermi Lause 4.2. Lineearinen pienimmän keskineliövirheen estimaattoi
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 21. syyskuuta 2007 Antti Rasila () TodB 21. syyskuuta 2007 1 / 19 1 Satunnaismuuttujien riippumattomuus 2 Jakauman tunnusluvut Odotusarvo Odotusarvon ominaisuuksia
Sovellettu todennäköisyyslaskenta B Antti Rasila 21. syyskuuta 2007 Antti Rasila () TodB 21. syyskuuta 2007 1 / 19 1 Satunnaismuuttujien riippumattomuus 2 Jakauman tunnusluvut Odotusarvo Odotusarvon ominaisuuksia
Differentiaali- ja integraalilaskenta 1 Ratkaisut 5. viikolle /
 MS-A8 Differentiaali- ja integraalilaskenta, V/7 Differentiaali- ja integraalilaskenta Ratkaisut 5. viikolle / 9..5. Integroimismenetelmät Tehtävä : Laske osittaisintegroinnin avulla a) π x sin(x) dx,
MS-A8 Differentiaali- ja integraalilaskenta, V/7 Differentiaali- ja integraalilaskenta Ratkaisut 5. viikolle / 9..5. Integroimismenetelmät Tehtävä : Laske osittaisintegroinnin avulla a) π x sin(x) dx,
Tehtävänanto oli ratkaista seuraavat määrätyt integraalit: b) 0 e x + 1
 0 e x + 1") Tehtävä : Tehtävänanto oli ratkaista seuraavat määrätyt integraalit: a) a) x b) e x + Integraali voisi ratketa muuttujanvaihdolla. Integroitava on muotoa (a x ) n joten sopiva muuttujanvaihto voisi olla
Tehtävä : Tehtävänanto oli ratkaista seuraavat määrätyt integraalit: a) a) x b) e x + Integraali voisi ratketa muuttujanvaihdolla. Integroitava on muotoa (a x ) n joten sopiva muuttujanvaihto voisi olla
Diskriminanttianalyysi I
 Diskriminanttianalyysi I 12.4-12.5 Aira Hast 24.11.2010 Sisältö LDA:n kertaus LDA:n yleistäminen FDA FDA:n ja muiden menetelmien vertaaminen Estimaattien laskeminen Johdanto Lineaarinen diskriminanttianalyysi
Diskriminanttianalyysi I 12.4-12.5 Aira Hast 24.11.2010 Sisältö LDA:n kertaus LDA:n yleistäminen FDA FDA:n ja muiden menetelmien vertaaminen Estimaattien laskeminen Johdanto Lineaarinen diskriminanttianalyysi
Ilkka Mellin Todennäköisyyslaskenta. Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat. Momenttiemäfunktio ja karakteristinen funktio
 Ilkka Mellin Todennäköisyyslaskenta Osa : Satunnaismuuttujat ja todennäköisyysjakaumat Momenttiemäfunktio ja karakteristinen funktio TKK (c) Ilkka Mellin (7) 1 Momenttiemäfunktio ja karakteristinen funktio
Ilkka Mellin Todennäköisyyslaskenta Osa : Satunnaismuuttujat ja todennäköisyysjakaumat Momenttiemäfunktio ja karakteristinen funktio TKK (c) Ilkka Mellin (7) 1 Momenttiemäfunktio ja karakteristinen funktio
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 8. marraskuuta 2007 Antti Rasila () TodB 8. marraskuuta 2007 1 / 18 1 Kertausta: momenttimenetelmä ja suurimman uskottavuuden menetelmä 2 Tilastollinen
Sovellettu todennäköisyyslaskenta B Antti Rasila 8. marraskuuta 2007 Antti Rasila () TodB 8. marraskuuta 2007 1 / 18 1 Kertausta: momenttimenetelmä ja suurimman uskottavuuden menetelmä 2 Tilastollinen
(b) Onko hyvä idea laske pinta-alan odotusarvo lähetmällä oletuksesta, että keppi katkeaa katkaisukohdan odotusarvon kohdalla?
 Onko hyvä idea laske pinta-alan odotusarvo lähetmällä oletuksesta, että keppi katkeaa katkaisukohdan odotusarvon kohdalla?") 6.10.2006 1. Keppi, jonka pituus on m, taitetaan kahtia täysin satunnaisesti valitusta kohdasta ja muodostetaan kolmio, jonka kateetteina ovat syntyneet palaset. Kolmion pinta-ala on satunnaismuuttuja.
6.10.2006 1. Keppi, jonka pituus on m, taitetaan kahtia täysin satunnaisesti valitusta kohdasta ja muodostetaan kolmio, jonka kateetteina ovat syntyneet palaset. Kolmion pinta-ala on satunnaismuuttuja.
Viikko 2: Ensimmäiset ennustajat Matti Kääriäinen matti.kaariainen@cs.helsinki.fi
 Viikko 2: Ensimmäiset ennustajat Matti Kääriäinen matti.kaariainen@cs.helsinki.fi Exactum C222, 5.-7.11.2008. 1 Tällä viikolla Sisältösuunnitelma: Ennustamisstrategioista Koneoppimismenetelmiä: k-nn (luokittelu
Viikko 2: Ensimmäiset ennustajat Matti Kääriäinen matti.kaariainen@cs.helsinki.fi Exactum C222, 5.-7.11.2008. 1 Tällä viikolla Sisältösuunnitelma: Ennustamisstrategioista Koneoppimismenetelmiä: k-nn (luokittelu
9. Tila-avaruusmallit
 9. Tila-avaruusmallit Aikasarjan stokastinen malli ja aikasarjasta tehdyt havainnot voidaan esittää joustavassa ja monipuolisessa muodossa ns. tila-avaruusmallina. Useat aikasarjat edustavat dynaamisia
9. Tila-avaruusmallit Aikasarjan stokastinen malli ja aikasarjasta tehdyt havainnot voidaan esittää joustavassa ja monipuolisessa muodossa ns. tila-avaruusmallina. Useat aikasarjat edustavat dynaamisia
Yhtälön oikealla puolella on säteen neliö, joten r. = 5 eli r = ± 5. Koska säde on positiivinen, niin r = 5.
 Tekijä Pitkä matematiikka 5 7..017 31 Kirjoitetaan yhtälö keskipistemuotoon ( x x ) + ( y y ) = r. 0 0 a) ( x 4) + ( y 1) = 49 Yhtälön vasemmalta puolelta nähdään, että x 0 = 4 ja y 0 = 1, joten ympyrän
Tekijä Pitkä matematiikka 5 7..017 31 Kirjoitetaan yhtälö keskipistemuotoon ( x x ) + ( y y ) = r. 0 0 a) ( x 4) + ( y 1) = 49 Yhtälön vasemmalta puolelta nähdään, että x 0 = 4 ja y 0 = 1, joten ympyrän
a) Sievennä lauseke 1+x , kun x 0jax 1. b) Aseta luvut 2, 5 suuruusjärjestykseen ja perustele vastauksesi. 3 3 ja
 Sievennä lauseke 1+x , kun x 0jax 1. b) Aseta luvut 2, 5 suuruusjärjestykseen ja perustele vastauksesi. 3 3 ja") 1 YLIOPPILASTUTKINTO- LAUTAKUNTA 1.10.2018 MATEMATIIKAN KOE PITKÄ OPPIMÄÄRÄ A-osa Ratkaise kaikki tämän osan tehtävät 1 4. Tehtävät arvostellaan pistein 0 6. Kunkin tehtävän ratkaisu kirjoitetaan tehtävän
1 YLIOPPILASTUTKINTO- LAUTAKUNTA 1.10.2018 MATEMATIIKAN KOE PITKÄ OPPIMÄÄRÄ A-osa Ratkaise kaikki tämän osan tehtävät 1 4. Tehtävät arvostellaan pistein 0 6. Kunkin tehtävän ratkaisu kirjoitetaan tehtävän
Matematiikan tukikurssi, kurssikerta 3
 Matematiikan tukikurssi, kurssikerta 3 1 Epäyhtälöitä Aivan aluksi lienee syytä esittää luvun itseisarvon määritelmä: { x kun x 0 x = x kun x < 0 Siispä esimerkiksi 10 = 10 ja 10 = 10. Seuraavaksi listaus
Matematiikan tukikurssi, kurssikerta 3 1 Epäyhtälöitä Aivan aluksi lienee syytä esittää luvun itseisarvon määritelmä: { x kun x 0 x = x kun x < 0 Siispä esimerkiksi 10 = 10 ja 10 = 10. Seuraavaksi listaus
T Luonnollisen kielen tilastollinen käsittely Vastaukset 3, ti , 8:30-10:00 Kollokaatiot, Versio 1.1
 T-61.281 Luonnollisen kielen tilastollinen käsittely Vastaukset 3, ti 10.2.2004, 8:30-10:00 Kollokaatiot, Versio 1.1 1. Lasketaan ensin tulokset sanaparille valkoinen, talo käsin: Frekvenssimenetelmä:
T-61.281 Luonnollisen kielen tilastollinen käsittely Vastaukset 3, ti 10.2.2004, 8:30-10:00 Kollokaatiot, Versio 1.1 1. Lasketaan ensin tulokset sanaparille valkoinen, talo käsin: Frekvenssimenetelmä:
Tilastollisen analyysin perusteet Luento 1: Lokaatio ja hajonta
 Tilastollisen analyysin perusteet Luento 1: ja hajonta Sisältö Havaittujen arvojen jakauma Havaittujen arvojen jakaumaa voidaan kuvailla ja esitellä tiivistämällä havaintoarvot sopivaan muotoon. Jakauman
Tilastollisen analyysin perusteet Luento 1: ja hajonta Sisältö Havaittujen arvojen jakauma Havaittujen arvojen jakaumaa voidaan kuvailla ja esitellä tiivistämällä havaintoarvot sopivaan muotoon. Jakauman
Yksisuuntainen varianssianalyysi (jatkoa) Heliövaara 1
 Heliövaara 1") Yksisuuntainen varianssianalyysi (jatkoa) Heliövaara 1 Odotusarvoparien vertailu Jos yksisuuntaisen varianssianalyysin nollahypoteesi H 0 : µ 1 = µ 2 = = µ k = µ hylätään tiedetään, että ainakin kaksi
Yksisuuntainen varianssianalyysi (jatkoa) Heliövaara 1 Odotusarvoparien vertailu Jos yksisuuntaisen varianssianalyysin nollahypoteesi H 0 : µ 1 = µ 2 = = µ k = µ hylätään tiedetään, että ainakin kaksi
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A050 Todennäköisyyslaskennan ja tilastotieteen peruskurssi B Satunnaismuuttujat ja todennäköisyysjakaumat Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto
MS-A050 Todennäköisyyslaskennan ja tilastotieteen peruskurssi B Satunnaismuuttujat ja todennäköisyysjakaumat Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto
Olkoon R S otosavaruuksien R ja S karteesinen tulo: Satunnaismuuttujien X ja Y järjestetty pari (X, Y) määrittelee kaksiulotteisen satunnaismuuttujan:
 määrittelee kaksiulotteisen satunnaismuuttujan:") Mat-.6 Sovellettu todennäköisslaskenta B Mat-.6 Sovellettu todennäköisslaskenta B / Ratkaisut Aiheet: Moniulotteiset satunnaismuuttujat ja todennäköissjakaumat Moniulotteisia jakaumia Avainsanat: Diskreetti
Mat-.6 Sovellettu todennäköisslaskenta B Mat-.6 Sovellettu todennäköisslaskenta B / Ratkaisut Aiheet: Moniulotteiset satunnaismuuttujat ja todennäköissjakaumat Moniulotteisia jakaumia Avainsanat: Diskreetti
JOHDATUS TEKOÄLYYN LUENTO 4.
 2009 CBS INTERACTIVE JOHDATUS TEKOÄLYYN LUENTO 4. TODENNÄKÖISYYSMALLINNUS II: BAYESIN KAAVA TEEMU ROOS Marvin Minsky Father of Artificial Intelligence, 1927 2016 PINGVIINI(tweety) :- true. Wulffmorgenthaler
2009 CBS INTERACTIVE JOHDATUS TEKOÄLYYN LUENTO 4. TODENNÄKÖISYYSMALLINNUS II: BAYESIN KAAVA TEEMU ROOS Marvin Minsky Father of Artificial Intelligence, 1927 2016 PINGVIINI(tweety) :- true. Wulffmorgenthaler
Derivaatan sovellukset (ääriarvotehtävät ym.)
") Derivaatan sovellukset (ääriarvotehtävät ym.) Tehtävät: 1. Tutki derivaatan avulla funktion f kulkua. a) f(x) = x 4x b) f(x) = x + 6x + 11 c) f(x) = x4 4 x3 + 4 d) f(x) = x 3 6x + 1x + 3. Määritä rationaalifunktion
Derivaatan sovellukset (ääriarvotehtävät ym.) Tehtävät: 1. Tutki derivaatan avulla funktion f kulkua. a) f(x) = x 4x b) f(x) = x + 6x + 11 c) f(x) = x4 4 x3 + 4 d) f(x) = x 3 6x + 1x + 3. Määritä rationaalifunktion
MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 5A Bayeslainen tilastollinen päättely Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy
MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 5A Bayeslainen tilastollinen päättely Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy
Luento 8: Epälineaarinen optimointi
 Luento 8: Epälineaarinen optimointi Vektoriavaruus R n R n on kaikkien n-jonojen x := (x,..., x n ) joukko. Siis R n := Määritellään nollavektori = (,..., ). Reaalisten m n-matriisien joukkoa merkitään
Luento 8: Epälineaarinen optimointi Vektoriavaruus R n R n on kaikkien n-jonojen x := (x,..., x n ) joukko. Siis R n := Määritellään nollavektori = (,..., ). Reaalisten m n-matriisien joukkoa merkitään
Estimointi. Vilkkumaa / Kuusinen 1
 Estimointi Vilkkumaa / Kuusinen 1 Motivointi Tilastollisessa tutkimuksessa oletetaan jonkin jakauman generoineen tutkimuksen kohteena olevaa ilmiötä koskevat havainnot Tämän mallina käytettävän todennäköisyysjakauman
Estimointi Vilkkumaa / Kuusinen 1 Motivointi Tilastollisessa tutkimuksessa oletetaan jonkin jakauman generoineen tutkimuksen kohteena olevaa ilmiötä koskevat havainnot Tämän mallina käytettävän todennäköisyysjakauman
Miten voidaan arvioida virheellisten komponenttien osuutta tuotannossa? Miten voidaan arvioida valmistajan kynttilöiden keskimääräistä palamisaikaa?
 21.3.2019/1 MTTTP1, luento 21.3.2019 7 TILASTOLLISEN PÄÄTTELYN PERUSTEITA Miten voidaan arvioida virheellisten komponenttien osuutta tuotannossa? Miten voidaan arvioida valmistajan kynttilöiden keskimääräistä
21.3.2019/1 MTTTP1, luento 21.3.2019 7 TILASTOLLISEN PÄÄTTELYN PERUSTEITA Miten voidaan arvioida virheellisten komponenttien osuutta tuotannossa? Miten voidaan arvioida valmistajan kynttilöiden keskimääräistä
Tilastollinen päättely II, kevät 2017 Harjoitus 2A
 Tilastollinen päättely II, kevät 07 Harjoitus A Heikki Korpela 3. tammikuuta 07 Tehtävä. (Monisteen tehtävä.3 Olkoot Y,..., Y n Exp(λ. Kirjoita vastaava tilastollisen mallin lauseke (ytf. Muodosta sitten
Tilastollinen päättely II, kevät 07 Harjoitus A Heikki Korpela 3. tammikuuta 07 Tehtävä. (Monisteen tehtävä.3 Olkoot Y,..., Y n Exp(λ. Kirjoita vastaava tilastollisen mallin lauseke (ytf. Muodosta sitten
E. Oja ja H. Mannila Datasta Tietoon: Luku 6
 6. HAHMONTUNNISTUKSEN PERUSTEITA 6.1. Johdanto Hahmontunnistus on tieteenala, jossa luokitellaan joitakin kohteita niistä tehtyjen havaintojen perusteella luokkiin Esimerkki: käsinkirjoitettujen numeroiden,
6. HAHMONTUNNISTUKSEN PERUSTEITA 6.1. Johdanto Hahmontunnistus on tieteenala, jossa luokitellaan joitakin kohteita niistä tehtyjen havaintojen perusteella luokkiin Esimerkki: käsinkirjoitettujen numeroiden,
HY, MTL / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIb, syksy 2017 Harjoitus 1 Ratkaisuehdotuksia
 HY, MTL / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIb, syksy 07 Harjoitus Ratkaisuehdotuksia Tehtäväsarja I Osa tämän viikon tehtävistä ovat varsin haastavia, joten ei todellakaan
HY, MTL / Matemaattisten tieteiden kandiohjelma Todennäköisyyslaskenta IIb, syksy 07 Harjoitus Ratkaisuehdotuksia Tehtäväsarja I Osa tämän viikon tehtävistä ovat varsin haastavia, joten ei todellakaan
T Luonnollisten kielten tilastollinen käsittely
 T-61.281 Luonnollisten kielten tilastollinen käsittely Vastaukset 3, ti 11.2.2003, 16:15-18:00 Kollokaatiot, Versio 1.1 1. Lasketaan ensin tulokset sanaparille valkoinen, talo käsin: Frekvenssimenetelmä:
T-61.281 Luonnollisten kielten tilastollinen käsittely Vastaukset 3, ti 11.2.2003, 16:15-18:00 Kollokaatiot, Versio 1.1 1. Lasketaan ensin tulokset sanaparille valkoinen, talo käsin: Frekvenssimenetelmä:
Talousmatematiikan perusteet: Luento 17. Integraalin sovelluksia kassavirta-analyysissa Integraalin sovelluksia todennäköisyyslaskennassa
 Talousmatematiikan perusteet: Luento 17 Integraalin sovelluksia kassavirta-analyysissa Integraalin sovelluksia todennäköisyyslaskennassa Motivointi Kahdella edellisellä luennolla olemme oppineet integrointisääntöjä
Talousmatematiikan perusteet: Luento 17 Integraalin sovelluksia kassavirta-analyysissa Integraalin sovelluksia todennäköisyyslaskennassa Motivointi Kahdella edellisellä luennolla olemme oppineet integrointisääntöjä
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 30. marraskuuta 2007 Antti Rasila () TodB 30. marraskuuta 2007 1 / 19 1 Lineaarinen regressiomalli ja suurimman uskottavuuden menetelmä Minimin löytäminen
Sovellettu todennäköisyyslaskenta B Antti Rasila 30. marraskuuta 2007 Antti Rasila () TodB 30. marraskuuta 2007 1 / 19 1 Lineaarinen regressiomalli ja suurimman uskottavuuden menetelmä Minimin löytäminen
MAT Todennäköisyyslaskenta Tentti / Kimmo Vattulainen
 MAT-5 Todennäköisyyslaskenta Tentti.. / Kimmo Vattulainen Vastaa jokainen tehtävä eri paperille. Funktiolaskin sallittu.. a) P A). ja P A B).6. Mitä on P A B), kun A ja B ovat riippumattomia b) Satunnaismuuttujan
MAT-5 Todennäköisyyslaskenta Tentti.. / Kimmo Vattulainen Vastaa jokainen tehtävä eri paperille. Funktiolaskin sallittu.. a) P A). ja P A B).6. Mitä on P A B), kun A ja B ovat riippumattomia b) Satunnaismuuttujan
Harjoitus 7: NCSS - Tilastollinen analyysi
 Harjoitus 7: NCSS - Tilastollinen analyysi Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen aiheita Tilastollinen testaus Testaukseen
Harjoitus 7: NCSS - Tilastollinen analyysi Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen aiheita Tilastollinen testaus Testaukseen
4.1. Olkoon X mielivaltainen positiivinen satunnaismuuttuja, jonka odotusarvo on
 Mat-2.090 Sovellettu todennäköisyyslasku A / Ratkaisut Aiheet: Avainsanat: Otanta Poisson- Jakaumien tunnusluvut Diskreetit jakaumat Binomijakauma, Diskreetti tasainen jakauma, Geometrinen jakauma, Hypergeometrinen
Mat-2.090 Sovellettu todennäköisyyslasku A / Ratkaisut Aiheet: Avainsanat: Otanta Poisson- Jakaumien tunnusluvut Diskreetit jakaumat Binomijakauma, Diskreetti tasainen jakauma, Geometrinen jakauma, Hypergeometrinen
Tilastollinen päättömyys, kevät 2017 Harjoitus 6B
 Tilastollinen päättömyys, kevät 7 Harjoitus 6B Heikki Korpela 8. helmikuuta 7 Tehtävä. Monisteen teht. 6... Olkoot Y,..., Y 5 Nµ, σ, ja merkitään S 5 i Y i Y /4. Näytä, että S/σ on saranasuure eli sen
Tilastollinen päättömyys, kevät 7 Harjoitus 6B Heikki Korpela 8. helmikuuta 7 Tehtävä. Monisteen teht. 6... Olkoot Y,..., Y 5 Nµ, σ, ja merkitään S 5 i Y i Y /4. Näytä, että S/σ on saranasuure eli sen
Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille. TKK (c) Ilkka Mellin (2004) 1
 Ilkka Mellin (2004) 1") Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (004) 1 Testit suhdeasteikollisille muuttujille Testit normaalijakauman parametreille Yhden otoksen t-testi Kahden
Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (004) 1 Testit suhdeasteikollisille muuttujille Testit normaalijakauman parametreille Yhden otoksen t-testi Kahden
Satunnaismuuttujien muunnokset ja niiden jakaumat
 Ilkka Mellin Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Satunnaismuuttujien muunnokset ja niiden jakaumat TKK (c) Ilkka Mellin (2007) 1 Satunnaismuuttujien muunnokset ja
Ilkka Mellin Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Satunnaismuuttujien muunnokset ja niiden jakaumat TKK (c) Ilkka Mellin (2007) 1 Satunnaismuuttujien muunnokset ja
Normaalijakaumasta johdettuja jakaumia
 Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2007) 1 Normaalijakaumasta johdettuja jakaumia >> Johdanto χ 2 -jakauma F-jakauma
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2007) 1 Normaalijakaumasta johdettuja jakaumia >> Johdanto χ 2 -jakauma F-jakauma
pitkittäisaineistoissa
 Puuttuvan tiedon käsittelystä p. 1/18 Puuttuvan tiedon käsittelystä pitkittäisaineistoissa Tapio Nummi tan@uta.fi Matematiikan, tilastotieteen ja filosofian laitos Tampereen yliopisto Puuttuvan tiedon
Puuttuvan tiedon käsittelystä p. 1/18 Puuttuvan tiedon käsittelystä pitkittäisaineistoissa Tapio Nummi tan@uta.fi Matematiikan, tilastotieteen ja filosofian laitos Tampereen yliopisto Puuttuvan tiedon
2 Pistejoukko koordinaatistossa
 Pistejoukko koordinaatistossa Ennakkotehtävät 1. a) Esimerkiksi: b) Pisteet sijaitsevat pystysuoralla suoralla, joka leikkaa x-akselin kohdassa x =. c) Yhtälö on x =. d) Sijoitetaan joitain ehdon toteuttavia
Pistejoukko koordinaatistossa Ennakkotehtävät 1. a) Esimerkiksi: b) Pisteet sijaitsevat pystysuoralla suoralla, joka leikkaa x-akselin kohdassa x =. c) Yhtälö on x =. d) Sijoitetaan joitain ehdon toteuttavia
(b) Tarkista integroimalla, että kyseessä on todella tiheysfunktio.
 Tarkista integroimalla, että kyseessä on todella tiheysfunktio.") Todennäköisyyslaskenta I, kesä 7 Harjoitus 4 Ratkaisuehdotuksia. Satunnaismuuttujalla X on ns. kaksipuolinen eksponenttijakauma eli Laplacen jakauma: sen tiheysfunktio on fx = e x. a Piirrä tiheysfunktio.
Todennäköisyyslaskenta I, kesä 7 Harjoitus 4 Ratkaisuehdotuksia. Satunnaismuuttujalla X on ns. kaksipuolinen eksponenttijakauma eli Laplacen jakauma: sen tiheysfunktio on fx = e x. a Piirrä tiheysfunktio.