TILASTOTIETEEN PERUSTEET, kl 2011
|
|
|
- Arto Kapulainen
- 8 vuotta sitten
- Katselukertoja:
Transkriptio
1 TILASTOTIETEEN PERUSTEET, kl 2011 Luku 3: TILASTOLLINEN KUVAILU Tässä luvussa esittelemme menetelmiä, joilla havaintomatriisin yhden sarakkeen eli yhden muuttujan havaintojen sisältämä informaatio kuvaillaan taulukoiden, graafisten esitysten ja tunnuslukujen avulla. 3.1 Frekvenssijakauma Muuttujan X yksiulotteisella frekvenssijakaumalla tarkoitetaan seuraavanlaisen taulukon sisältöä X:n mahdolliset absoluuttinen suhteellinen arvot t. luokat frekvenssi frekvenssi (%) A 1 m 1 p 1 A 2 m 2 p 2... A r m r p r yhteensä n 100 Absoluuttinen frekvenssi m k kertoo arvon A k saaneiden tai luokkaan A k kuuluvien havaintoyksikköjen lukumäärän; k = 1, 2,..., r N. Suhteellinen frekvenssi p k = m k /n kertoo luokkaan A k kuuluvien suhteellisen osuuden, joka tavallisesti ilmaistaan prosentteina. Tämä esitystapa käy kaikilla mitta-asteikoilla. Luokittelu- ja järjestysasteikon muuttujilla luokat ovat yleensä valmiina. Välimatka- ja suhdeasteikon muuttujille joutuu yleensä ensin suorittamaan arvojen luokittelun (ks. 3.6). Esim Eräälle tilastotieteen kurssille osallistuneiden TaTK:n opiskelijoiden koulutusohjelman jakauma oli seuraavanlainen: 1
 A 1 m 1 p 1 A 2 m 2 p 2.")
2 koulutusohjelma lkm % markkinointi kansantaloustiede laskentatoimi jokin muu 8 12 yhteensä Jakauman moodi eli tyyppiarvo, merkitään Mo, on se arvo tai luokka, jonka frekvenssi on suurin. Esimerkissä 3.1.koulutusohjelman jakauman moodi on markkinointi. Seuraavassa esitetään pylväskuvio koulutusohjelman jakaumasta Markkinointi KTT Laskentatoimi Jokin muu Pystyssä olevien pylväiden hahmottaminen ja niiden suuruuksien vertailu ei välttämättä toimi yhtä hyvin kuin vastaavan palkkikuvion palkkien, jotka ovat alekkain vaakasuorassa olevia pylväitä. 2

3 Opiskelijoita Markkinointi KTT Laskentatoimi Jokin muu Huomattavasti tehokkaampi data-mustesuhde (data-ink ratio) luokitellun muuttujan jakauman graafiselle esitykselle saadaan pisteviivakuvion (dotchart) avulla: Markkinointi KTT Laskentatoimi Jokin muu Opiskelijoita Kaikissa em. kuvioissa voidaan absoluuttisten frekvenssien asemesta kuvata eri luokkien suhteelliset frekvenssit. Piirakkakuviota (pie chart) pidetään perustellusti huonoimpana niistä graafisista esityksistä, joita yleisesti käytetään luokitellun frekvenssijakauman kuvaamiseen (ks. esim. ~ihaka/courses/787/ lectures-presentation-graphics.pdf). Lopuksi todettakoon, että kun luokkia on näinkin vähän kuin tässä esimerkissä, niin tutkimusraportissa ison tilan vievän kuvion asemesta säästeliäämpää ja vähintään yhtä informatiivista on tyytyä yksinkertaiseen taulukkoon tai sen sisältämän muutaman luvun esittämiseen tekstissä. 3
 pidetään perustellusti huonoimpana niistä graafisista esityksistä, joita yleisesti käytetään luokitellun frekvenssijakauman kuvaamiseen (ks. esim. http://www.stat.auckland.")
4 3.2. Jatkuvat muuttujat: luokittelematon aineisto Tarkastelemme nyt luonteeltaan jatkuvan välimatka-asteikon muuttujan jakauman kuvaamista erilaisia graafisia esitystapoja ja tunnuslukuja käyttäen. Esimerkkiaineiston tarjoavat muuttujan PITUUSM mittaustulokset kl 2009 pidetyn kurssin Tilastotieteen perusteet A osallistujista (n = 50). R-ohjelmassa funktiokutsulla sort(pituusm) suuruusjärjestykseen lajitellut havainnot (cm) olivat: [1] [20] [39] Kun muuttujan X alkuperäiset havainnot x 1,..., x n järjestetään pienimmästä suurimpaan, niin käytetään merkintää x (i) = järjestyksessä i:nneksi pienin havaintoarvo, i = 1,..., n, jolloin x (1) x (2) x (n). Näillä merkinnöillä mm. x (1) on muuttujan X pienin arvo eli minimi ja x (n) suurin arvo eli maksimi, ja lukupari (x (1), x (n) ) on vaihteluväli. Tässä aineistossa vaihteluväli on (157 cm, 193 cm), joka saadaan R-funktion range() avulla argumenttina PITUUSM. Pituusarvojen runko-lehtikuvio saadaan funktiolla stem() ja on seuraavan näköinen The decimal point is 1 digit(s) to the right of the Sitten piirrämme pistekuvion eli yksiulotteisen parvikuvion Pituus (cm) 4
![R-ohjelmassa funktiokutsulla sort(pituusm) suuruusjärjestykseen lajitellut havainnot (cm) olivat: [1] 157 159 160 160 160 160 160 160 161 161 163 164 165 165 165 165 166 166 166 [20] 167 167 168 168](/docs-images/42/3939305/images/page_4.jpg "170 170 170 171 172 172 174 175 175 175 176 176 176 177 177 [39] 178 180 182 182 182 182 183 185 186 188 188 193 Kun muuttujan X alkuperäiset havainnot x 1,.")
5 Tämä kuvio noudattaa erinomaisesti kuuluisan tilastograafikon Edward R. Tuften periaatetta: Above all else, show the data! Tätä iskulausetta on sittemmin jatkettu:... all the data, and nothing but the data Sijaintiluvut Yksiulotteisen empiirisen jakauman tunnuslukuja ovat mm. sijainti- eli keskiluvut, hajontaluvut, vinousluvut ja huipukkuusluvut. Sijaintilukuja ovat mm. moodi, mediaani sekä aritmeettinen keskiarvo. Hajontalukuja ovat mm. vaihteluväli, kvartiiliväli ja keskihajonta. Pituuden moodi näyttäisi olevan 160 cm, koska tämä yksittäinen pituusarvo näyttää esiintyvän aineistossa muita arvoja suuremmalla frekvenssillä. Jatkuvan muuttujan tapauksessa moodi kannattaa mieluummin määrätä luokitellusta aineistosta (ks ), koska varsinkin pienillä aineistoilla yksittäisistä havainnoista laskettu moodi voi olla hyvinkin satunnainen. Jakauman mediaani, merk. Md, määritellään (a) Md = x (n+1)/2 kun n on pariton ja (b) Md = (x (n/2) + x (n/2+1) )/2, kun n on parillinen. Esimerkkiaineistossamme n = 50 on parillinen, joten mediaani on havaintoarvojen x (25) = 170 ja x (26) = 170 keskiarvo eli Md = 170 cm. Mediaani jakaa järjestyksessä olevat havainnot keskeltä kahtia niin, että puolet jakaumasta on sen vasemmalla ja puolet oikealla puolella. Mediaani on sekä arvoltaan että tulkinnaltaan erittäin stabiili tunnusluku. Sen arvoon ei vaikuta jakauman muoto (esim. vinous tai paksuhäntäisyys) eivätkä jotkin muista havainnoista huomattavasti poikkeavat havainnot. Jakauman kvartiilit jakavat järjetetyt havainnot neljään yhtä suureen osaan: alakvartiili Q 1 on sellainen X:n mahdollinen arvo, jonka vasemmalle puolelle jää 25% jakaumasta. keskikvartiili Q 2 = Md eli mediaani, ja yläkvartiili Q 3 on sellainen X:n mahdollinen arvo, jonka vasemmalle puolelle jää 75% jakaumasta. 5

6 Esimerkkiaineistossamme alakvartiili on Q 1 = x (13) = 165 cm ja yläkvartiili Q 3 = x (38) = 177 cm. Kvartiilit ovat erikoistapaus laajemmasta sijaintilukujen luokasta, joita yhteisesti kutsutaan fraktiileiksi eli kvantiileiksi. Jakauman p-fraktiili on sellainen muuttujan X mahdollinen arvo q p, jota pienempiä arvoja havaintoaineistossa on p %. Tässä p:n ei tarvitse olla kokonaisluku. Huom. Laboratoriolääketieteessä käytetään usein 2.5%:n ja 97.5% fraktiileja rajaamaan jonkin kliiniskemiallisen tai fysiologisen muuttujan 95% viiteväli eli sellainen mahdollisten laboratorioarvojen väli, jolle 95% terveen t. normaalin väestön viitearvot sijoittuisivat. Fraktiilien määrääminen empiirisessä jakaumassa ei ole yksikäsitteistä. Esimerkiksi R:n funktio quantile() tarjoa 9 erilaista vaihtoehtoista laskukaavaa fraktiileille! Seuraavassa esittelemme R:n oletusarvoisesti tarjoaman laskutavan. Kun otoskoko on n, ja halutaan p-fraktiili q p, jossa 0 < p < 100, niin toimitaan seuraavasti: (1.) lasketaan k = (n 1)p/ , (2.) merkitään k:lla luvun k kokonaisosaa k = max{j N j k } = k, (3.) lasketaan k :n desimaaliosasta painokerroin w = k k (0 w < 1), (4.) lasketaan p-fraktiili q p havaintojen x (k) ja x (k+1) painotettuna keskiarvona q p = (1 w)x (k) + wx (k+1). Jos k sattuu olemaan kokonaisluku, niin k = k ja w = 0, jolloin q p = x (k). Mediaanin tapauksessa tämä kuin myös kaikki muut vaihtoehtoiset laskutavat tiivistyvät kahteen edellä esitettyyn varianttiin, jotka määräytyvät aineiston koon n parillisuudesta tai parittomuudesta. Välimatka- tai suhdeasteikollisen muuttujan X aritmeettinen keskiarvo, lyhyemmin keskiarvo, merk. x, on kaikkien havaintoarvojen x i summa jaettuna aineiston koolla n. x = 1 n x i. n Keskiarvo on teoreettisen jakauman odotusarvon µ = E(X) empiirinen vastine. Se kuvaa havaintojen jakauman tasapainopistettä. 6

7 Esimerkkiaineistossamme keskiarvo, joka saadaan R-funktion mean() kutsulla, on x = ( )/50 = cm. Kun jakauma on likimain normaalijakauman muotoinen eli symmetrinen, yksihuippuinen ja riittävän ohuthäntäinen jakauman, niin keskiarvo on optimaalinen tunnusluku kuvaamaan jakauman sijaintia. Jos jakauma on kovin paksuhäntäinen tai vino jompaan kumpaan suuntaan, jolloin siinä on joitakin hyvin suuria tai hyvin pieniä arvoja, niin tällaiset muusta aineistosta poikkeavat arvot vaikuttavat keskiarvoon suurella painolla. Niinpä keskiarvoa ei pidetä jakauman muodon suhteen yhtä robustina eikä yksittäisten poikkeavien havaintojen suhteen yhtä resistanttina tunnuslukuna kuin esimerkiksi mediaania. Geometrinen G keskiarvo määritellään G = (x 1 x 2... x n ) 1/n = exp { 1 n } n log(x i ). Se edellyttää vähintään suhdeasteikon mittaustasoa ja kaikkien havaintoarvojen x i positiivisuutta. Geometrista keskiarvoa käytetään sijaintilukuna tyypillisesti oikealle vinojen jakaumien yhteydessä. Se on optimaalinen tunnusluku kun havainnot noudattavat likimain log-normaalijakaumaa, jolloin G Md. Yleisesti pätee epäyhtälö G x. Pituusjakaumassa G = cm Hajontaluvut Empiirisessä jakaumassa havaintoarvojen vaihtelua kuvaavia tunnuslukuja kutsutaan hajontaluvuiksi. Näitä ovat mm. edellä määritelty vaihteluväli Ra = (x (1), x (n) ) kuin myös kvartiiliväli, kvartiilivälin pituus sekä keskihajonta. Kvartiiliväli QI = [Q 1, Q 3 ] kattaa aineiston keskipuolikkaan eli keskimmäiset 50% muuttujan X havaituista arvoista. Kun lasketaan ylä- ja alakvartiilin erotus, saadaan hajontaluku nimeltään kvartiilivälin pituus Q = Q 3 Q 1. Pituusjakauman kvartiiliväli on QI = [165 cm, 177 cm] ja kvartiilivälin pituus Q = = 12 cm Keskihajonta eli lyhyemmin hajonta, merk. s (tai s x kun halutaan koros- 7

8 taa, että kyse on muuttujan X hajonnasta) lasketaan kaavalla s = 1 n (x i x) n 1 2. Hajonnan neliö s 2 on jakauman empiirinen varianssi joka on teoreettisen jakauman varianssin σ 2 = D 2 (X) = var(x) empiirinen vastine. Varianssi on additiivisuutensa vuoksi teoreettisissa tarkasteluissa tärkeä tunnsuluku. Keskihajonta on kuitenkin käytännössä käyttökelpoisempi ja selkeämmin tulkittavissa, koska sen mittayksikkö on sama kuin muuttujan X itsensä. Esimerkissämme pituusdatan havaintojen keskihajonta on R-funktion sd() kutsun tuloksena 1 s = 50 1 [( )2 + + ( ) 2 ] = = 9.14 cm. Keskihajonta on parhaiten tulkittavissa, jos jakauma muistuttaa likimain normaalijakaumaa eli on yksihuippuinen sekä riittävän symmetrinen, ja ohuthäntäinen. Ideaalitilanteessa eli puhtaassa normaalijakaumassa väli [ x s, x + s] sisältää n. 68% jakauman keskeltä, väli [ x 2s, x + 2s] kattaa n. 95%, ja välin [ x 3s, x + 3s] sisälle jää miltei koko jakauma. Jos muuttuja X on suhdeasteikollinen, jolloin sen kaikki arvot ovat ei-negatiivisia, ja kovin vino oikealle, em. tulkinnat eivät päde. Jo yksi keskihajonta keskiarvosta vasemmalle saattaa viedä reaaliakselin negatiiviselle puolikkaalle. Tällöin väleillä [ x ks, x + ks], jossa k = 1, 2,..., ei ole mielekästä tulkintaa. Sen sijaan esim. kvartiileihin tai muihin fraktiileihin perustuvat välit säilyttävät tulkintansa minkämuotoisessa jakaumassa tahansa. 3.5 Otoskertymäfunktio ja laatikko-janakuvio Järjestettyjen havaintojen pohjalta voidaan myös tarkastella muuttujan otoskertymäfunktiota F (x). Tämä funktio määritellään F (x) = #{i x (i) x} n = n I (,x] (x (i) ), jossa I A : R {0, 1} tarkoittaa joukon A R indikaattorifunktiota s.e. I A (a) = 1, kun a A ja I A (a) = 0 kun a / A jok. A R. Toisin sanoen F (x) on kaikissa pisteessä oikealta jatkuva porrasfunktio, joka lähtee tasolta 0, kun x < x (1), hyppää kullakin i = 1, 2,..., n 1 tasolle i/n, kun x = x (i), pysyen tällä tasolla, kunnes arvolla x = x (i+1) nousee tasolle (i + 1)/n, jne. ja päätyy lopulta tasolle 1, kun x x (n). Seuraavassa pituuden jakauman otoskertymäfunktion kuvaaja. 8

9 Otoskertymä Pituus (cm) R-funktio ecdf(x) laskee argumenttina annetun vektorin X otoskertymäfunktion arvot, ja plot(ecdf(x)) piirtää ao. kuvaajan. Kuviossa on lisäksi tasoja 25%, 50% ja 75% merkitty katkoviivoin, ja niiden avulla voidaan määrätä graafisesti jakauman kvartiilit, jotka siis ovat Q 1 = 165 cm, Md = Q 2 = 170 cm ja Q 3 = 177 cm. Laatikko-janakuvion tai lyhyemmin laatikkokuvion perusversio tiivistää jakauman kuvauksen viiteen tunnuslukuun (five-number summary): minimi, alakvartiili, mediaani, yläkvartiili ja maksimi Pituus (cm) Nykyään suositumpi ja mm. R-ohjelmassa funktion boxplot() oletusarvoisesti soveltama laatikkokuvion piirtämisperiaate on hieman mutkikkaampi. Siinä määritellään ensin ns. sisäaidat alempi sisäaita = Q Q, ylempi sisäaita = Q Q Laatikosta lähtevät janat tai viikset piirretään nyt siten, että alemman janan toinen päätepiste on pienin havaintoarvo x i, joka on alempaa sisäaitaa suurempi, kun taas yläkvartiilista lähtevän jana päättyy suurimpaan havaintoon x i, joka jää ylempää sisäaitaa pienemmäksi. Sisäaitaa pienemmät ja ulkoaitaa suuremmat havaintoarvot ovat mahdollisia oudokkeja (outlier) 9
 Nykyään suositumpi ja mm. R-ohjelmassa funktion boxplot() oletusarvoisesti soveltama laatikkokuvion piirtämisperiaate on hieman mutkikkaampi.")
10 eli vieraita havaintoja, jotka merkitään yksitellen esim. pienellä ympyrällä o. Jos jakauma on kovin vino tai huipukas suhteessa normaalijakaumaan, niin tällaisia havaintoja tulee hyvinkin helposti ilman, että niissä sinänsä on mitään outoa. Joissakin laatikkokuvion versioissa otetaan käyttöön vielä lisäksi ns. ulkoaidat, jotka ovat 3 Q mittayksikön päässä ala- ja yläkvartiilista. Näiden aitojen ulkopuolelle sijoittuvia vahvasti poikkeavia arvoja (extremes) merkitään ympyrän sijaan esim. tähdellä eli asteriksilla * Jatkuvan muuttujan luokiteltu jakauma Luokittelemme nyt pituuden käyttäen 5 cm luokkavälejä. Seuraavassa taulukossa on yksityiskohtaisesti esitetty luokittelun tulokset: luokkarajat sekä frekvenssijakauman erilaiset frekvenssit. Pyöris- Luo- Abs. Suht. Summa- Suht. tetyt Todelliset kan frek- frek- frek- summaluokka- luokkarajat kes- venssi venssi venssi frekv. rajat a k 1, a k kus m k p k M k P k , , , , , , , , Yhteensä Taulukon vasemman laidan 1. sarakkeessa on annettu eri luokkien pyöristetyt luokkarajat olettaen, että mittaustulokset on pyöristetty lähimpään kokonaiseen senttimetriin. Tämän pohjalta kunkin luokan A k (k = 1,..., r) todelliset luokkarajat määräytyvät suraavasti: todellinen alaraja a k 1 on 0.5 cm pyöristettyä alarajaa pienempi ja todellinen yläraja a k on pyöristettyä ylärajaa 0.5 cm suurempi. Luokassa A k luokkavälin pituus (tai leveys) k on todellisen ylärajan ja todellisen alarajan erotus: k = a k a k 1. Luokkakeskus ẋ k on todellisen alarajan ja todellisen ylärajan keskiarvo: ẋ k = (a k + a k 1 )/2. 10
 merkitään ympyrän sijaan esim. tähdellä eli asteriksilla *. 3.6.")
11 Kahdessa oikeanpuoleisessa sarakkeessa olevat luvut saadaan seuraavalla periaatteella: absoluuttinen summafrekvenssi eli kumulatiivinen frekvenssi M k = k j=1 m j, suhteellinen summafrekvenssi P k = k j=1 p j = M k /n. Jos havaintoaineisto on valmiiksi luokiteltu ja taulukoitu edellä olevaan tapaan, ja alkuperäisiä havaintoarvoja ei ole käytettävissä, niin muuttujan X aritmeettinen ja geometrinen keskiarvo sekä keskihajonta saadaan likimääräisesti lasketuksi eri luokkien frekvenssien ja luokkakeskusten pohjalta seuraavasti. { } x = 1 r 1 r m k ẋ k, G = exp m k log(ẋ k ), n n k=1 k=1 s = 1 r m k (ẋ k x) n 1 2 k=1 Tässä aineistossa näiden tunnuslukujen arvot olivat x = 1 ( ) = 172 cm, 50 { } 1 Ḡ = exp [2 log(157) log(192)] = cm, 50 1 s = 50 1 [2 ( ) ( ) 2 ] = 8.86 cm Histogrammi ja frekvenssimonikulmio Histogrammissa kunkin luokan A k (k = 1,..., r) absoluuttista tai suhteellista frekvenssiä kuvaa pylväs, jonka korkeus f k määräytyy seuraavasti: f k = korkeus = suhteellinen frekvenssi luokkaleveys = p k k, k = 1,..., k. Niinpä pylvään korkeus f k on esim. toiseksi alimmassa luokassa 8%/5 cm = 1.6 per 100 cm, ja luokassa cm se on 18%/5 cm = 3.6 per 100 cm. Pylvään korkeus kuvaa siis ao. luokan frekvenssitiheyttä. Pylvään sijainnin ja leveyden x-akselilla määräävät ao. luokan todelliset luokkarajat. Kun kyseessä on jatkuva muuttuja, niin pylväät piirretään kiinni toisiinsa. Näiden periaatteiden mukaan on R-funktion hist() avulla piirretty pituuden histogrammi, joka esitetään seuraavassa kuviossa. Jakauman moodiksi 11

12 voidaan nyt määrätä Mo = 167 cm eli korkeinta pylvästä vastaava luokkakeskus. Tiheys (per 100 cm) Pituus (cm) Histogrammin ajatellaan usein toimivan parametrittomana estimaattina taustalla olevassa perusjoukossa ao. muuttujalle oletetun jakauman jatkuvalle tiheysfunktiolle f(x). Niinpä y-akselin asteikoksi onkin luontevaa ottaa kunkin luokan suhteellinen frekvenssitiheys. Näin normitettujen pylväiden kokonaispinta-ala summautuu arvoon 1 eli 100%. Todettakoon, että R-ohjelman histogrammifunktion hist() oletusarvoinen luokittelutapa ei noudata edellä esitettyä oikeaoppista piirtämisperiaatetta, jonka mukaan pylväiden sijainnin x-akselilla määräävät olettamamme pyöristysperiaatteen (eli pyöristys lähimpään pyöreään lukuun) mukaiset tarkat luokkarajat. Niinpä mm. tässä esimerkissä funktiokutsulla hist(pituusm) ilman lisäargumentteja saadaan histogrammi, jonka pylväiden leveydet ovat kylläkin kaikki 5 cm, mutta esim. alimpaan luokkaan tulevat sisällytetyksi kaikki pyöristetyt pituusarvot väliltä cm, ja kuitenkin vastaava pylväs on sijoitettu x-akselilla välille ]155, 160] eli käytännössä peräkkäisten luokkien pyöristettyjen ylärajojen väliin. 12

13 Histogram of PITUUSM Frequency PITUUSM Tässä histogrammissa pylväiden korkeudet ovat itse asiassa samat kuin luokkien frekvenssit, mikä käy päinsä, kun luokittelu on tasavälinen. Pienissä aineistoissa, joiden havaintoarvot ovat vahvasti pyöristettyjä, voidaan nähdä isojakin satunnaisia eroja eri luokitusten pohjalta piirrettyjen histogrammien välillä. Kun aineisto on kooltaan suuri, eikä muuttujan arvoja ole voimakkaasti pyöristetty, luokittelun ja luokkarajojen yksityiskohdilla ei ole enää kovin suurta merkitystä lopputuloksen muotoon, vaikka käytettäisiin suhteellisen kapeitakin luokkia. Huomattakoon silti, että funktiolla hist() saadaan piirretyksi haluttuja tarkkoja luokkarajoja noudattava histogrammi, kun funktiokutsussa lisäargumenttina annetaan vastaavien katkaisupisteiden (breaks) vektori esim. tyyliin breaks = *(0:10). Näin on menetelty mm. ensimmäisessä histogrammissa edellä Vino jakauma ja pyöristys alaspäin Tarkastelemme nyt luokittelua ja histogrammin piirtämistä jatkuvalle muuttujalle, jonka arvot on tapana pyöristää lähimpään pienempään pyöreään lukuun (kuten ikä täysinä vuosina) ja jonka luokittelussa on syytä käyttää vaihtelevansuuruisia luokkaleveyksiä k. Oheisessa taulukossa esitetään saman opiskelijaryhmän ikien luokiteltu frekvenssijakauma. 13

14 Pyöris- Luo- Abs. Suht. Summa Suht. tetyt Todelliset kan frek- frek- frek- summaluokka- luokkarajat kes- venssi venssi venssi frekv. rajat (v) a k 1, a k kus m k p k M k P k 19 19, , , , , Yhteensä Nyt kahden alimman luokan luokkaleveydet ovat 1 v, kolmannen leveys 2 v, neljännen 3 v, ja ylimmän luokan leveys on 5 v. Niinpä histogrammipylväiden korkeudet eli frekvenssitiheydet f k ovat luokittain f 1 = 42%/1 v = 42 per 100 v, f 2 = 34%/1 v = 34 per 100 v, f 3 = 12%/2 v = 6 per 100 v, f 4 = 4%/3 v = 1.33 per 100 v, f 5 = 8%/6 v = 1.33 per 100 v. Density IKA 3.9. Frekvenssimonikulmio ja summakäyrä Tilastotieteen sekä yliopistotason että lukion oppikirjoissa pidetään edelleen tärkeänä opeteltavana kuviotyyppinä frekvenssimonikulmiota, vaikka sitä ei oppikirjojen ulkopuolella nykyään käytännössä juurikaan kohtaa. Kuvion ytimen muodostaa tasokoordinaatistoon piirretty murtoviiva, jonka käännepisteiden koordinaatit ovat (ẋ k, f k ) = (luokkakeskus, pylvään korkeus); k = 1,..., r. Murtoviiva alkaa kuitenkin alinta luokkaa edeltävän tyhjän luo- 14

15 kan luokkakeskuksesta ẋ 0 tasolta 0 ja päättyy lopulta tasolle 0 ylintä luokkaa seuraavan tyhjän luokan luokkakeskuksen ẋ r+1 kohdalla. Ohessa pituusarvoista piirretty frekvenssipolygoni, jonka periaatetta havainnollistaa taustaksi pisteviivoin hahmotettu vastaava histogrammi. Tiheys (per 100 cm) Pituus (cm) Summakäyrä on murtoviivakuvio, jolla havainnollistetaan jatkuvan muuttujan summafrekvenssien kehitystä luokasta toiseen. Tämä on alkuperäisistä havainnoista piirrettävän otoskertymäfunktion porraskuvion vastine luokitellulle aineistolle, ja sitä voidaan myös pitää taustalle oletetun jatkuvan teoreettisen jakauman kertymäfunktion F (x) graafisena estimaattina. Summakäyrän murtoviiva lähtee tasolta 0 (%) ja päätyy tasolle 1 = 100%, ja sen käännepisteet ovat (a k, P k ) = (todellinen yläraja, suhteellinen summafrekvenssi); k = 1,..., r. Kuvion avulla voi myös arvioida graafisesti mediaanin ja kvartiilien arvoja luokitellusta aineistosta samalla periaatteella kuin otoskertymäfunktion kuvaajastakin. Suht. summaf. (%) Q1 Md Q Pituus (cm) 15

16 Mediaanin ja kvartiilien graafiset arviot ovat (sentin tarkkuudella) Md = 171 cm, Q 1 = 165 cm ja Q 3 = 179 cm. Mediaanin ja yläkvartiilin arviot siis hieman poikkeavat niistä tarkoista luvuista, jotka laskettiin alkuperäisistä havainnoista Histogrammien silotus Histogrammin (kuin myös frekvenssimonikulmion) ongelmana on kuvion muodon riippuvuus luokkarajoja ja luokkien leveyksiä koskevista valinnoista, jotka usein ovat varsin mielivaltaisia. Erityisesti pienissä ja keskisuurissa aineistoissa tiheä luokitus, joka sisällöllisesti voi olla hyvinkin perusteltavissa, tuottaa helposti satunnaisia lopputuloksia. Riittävän harvalla luokituksella päästään ehkä stabiilimpaan kuvaan, mutta tällöin jakauman jotkin olennaiset yksityiskohdat saattavat jäävät pimentoon. Toisaalta jatkuvan muuttujan luokittelu merkitsee myös histogrammin väkivaltaista diskretoimista, ts. tiheyden muutokset luokkarajojen kohdalla näyttävät epäjatkuvilta hyppäyksiltä. Tämä pykälittäisyys haittaa myös kahden eri ryhmän histogrammien vertailua samassa kuvassa. Tietokoneiden ja ohjelmien kehittyminen on luonut mahdollisuuden piirtää histogrammin sijaan sopivalla menetelmällä silotettu tai tasoitettu (smoothed) histogrammi, jota voidaan pitää tavanomaista histogrammia luontevampana graafisena estimaattina taustalle oletetulle jatkuvalle tiheysfunktiolle f(x). Tiheys (per cm) Pituus (cm) Ohessa ydinmenetelmällä (kernel method) silotettu histogrammi, joka esittää pituuden tiheysfunktion f(x) ydinestimaattoria f(x). Ydinestimaattorin 16

17 arvo jokaisella x lasketaan havainnoista x 1,..., x n seuraavasti f(x) = 1 n n 1 h K ( x xi jossa K(z) on valittu ydinfunktio, ja h on silotusparametri tai kaistanleveys (bandwidth). Tässä käytetään Gaussin ydintä eli K(z) = ϕ(z) eli N(0, 1)-jakauman tiheysfunktiota ja kaistanleveytenä on h 3.7 cm. Huomaa myös x-akselin matonrimpsut (rugplot). Ne kuvaavat pistekuvion tapaan aineiston havaittuja arvoja, joiden pohjalta silotettu histogrammi on piirretty. h ), Todettakoon, että niin histogrammi ja frekvenssimonikulmio kuin myös silotettu histogrammi antavat sen vaikutelman, että pituuden jakauma tässä opiskelijajoukossa olisi sekä kaksihuippuinen että jossain määrin oikealle vino. Tällaiset piirteet saattavat syntyä pienten ja keskisuurten aineistojen pohjalta piirrettyihin kuvioihin pelkästään sattumalta, vaikka todellinen jakauma olisi symmetrinen ja yksihuippuinen. Tässä tapauksessa kaksihuippuisuuteen ja vinouteen on kuitenkin selkeä selitys: aineistossa on 33 naista ja 17 miestä. Kummallakin sukupuolella pituuden luonnollinen jakauma lienee varsin lähellä normaalijakaumaa Kahden ryhmän vertailu Esitämme nyt rinnakkain tai alekkain naisten ja miesten pituusjakaumat eri kuviotyyppejä käyttäen. Ensin ryhmittäinen pistekuvio naiset miehet Pituus (cm) Sitten ryhmittäinen laatikkokuvio 17
, Todettakoon, että niin histogrammi ja frekvenssimonikulmio kuin myös silotettu histogrammi antavat sen vaikutelman, että pituuden jakauma tässä opiskelijajoukossa olisi sekä kaksihuippuinen että")
18 naiset miehet Pituus (cm) Lopuksi silotetut histogrammit molemmille sukupuolille Tiheys (per cm) Naiset Miehet Pituus (cm) Luokittelu- ja järjestysasteikon muuttujille havainnollisen tavan esittää prosenttijakaumia eri ryhmien välillä tarjoavat alekkain asetetut osiin jaetut palkkikuviot. 18

19 19
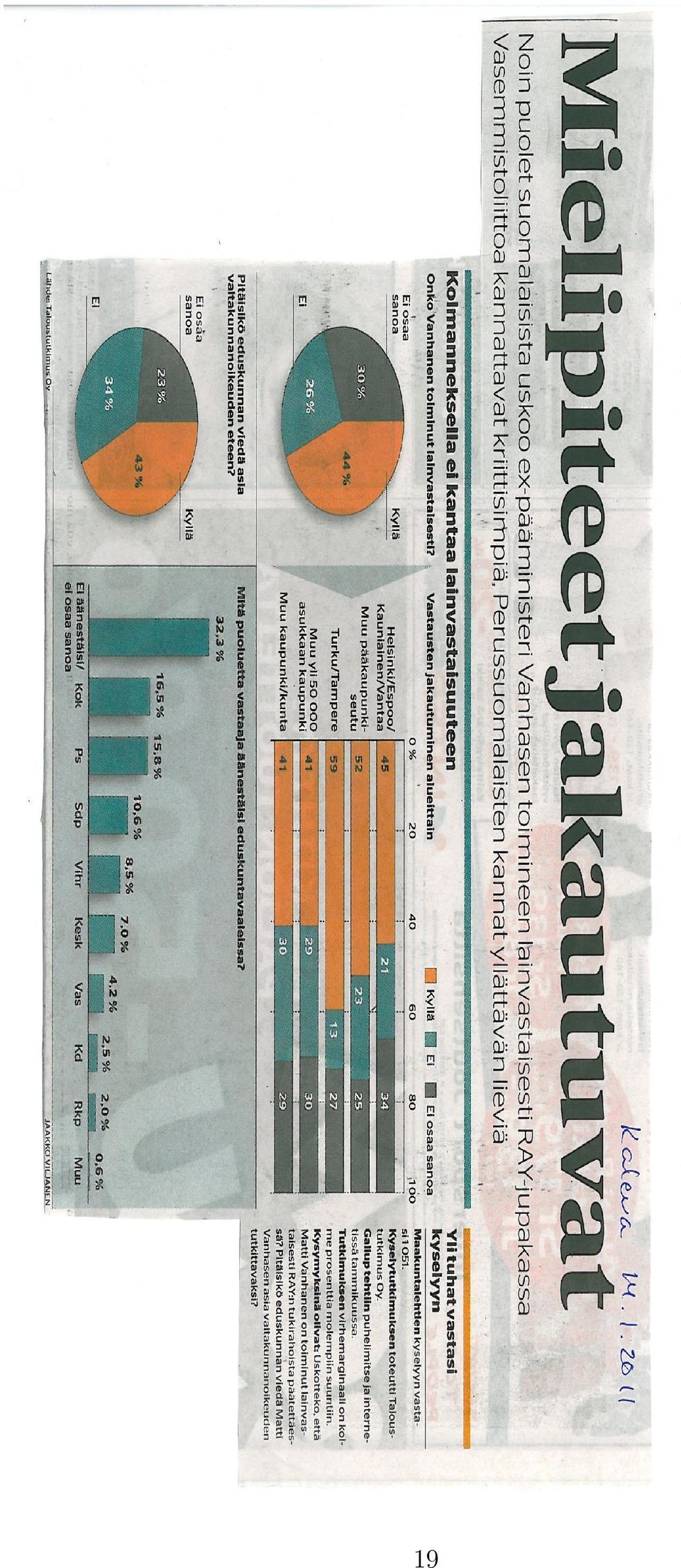
20 3.12. Taulukkoja koskevat suositukset Hyvä taulukko on sekä tiivis ja luettava että mahdollisimman paljon olennaista informaatiota välittävä. Näiden vaatimusten samanaikainen täyttäminen ei ole helppoa, ja taulukon laadinta onkin vaikeampi tehtävä kuin yleensä ajatellaan. Kaikkiin tilanteisiin yleispäteviä neuvoja ei voi antaa, mutta eräitä muodollisia periaatteita kannattaa pyrkiä noudattamaan. (T1) Taulukon on oltava mahdollisimman yksinkertainen ja itsensä selittävä. Se on kyettävä ymmärtämään Aineisto ja menetelmät -lukuun perehtymisen jälkeen ilman tukeutumista tekstiin. (T2) Taulukossa on otsikko, joka kertoo, mistä aineistosta tai sen osasta on kysymys ja mitä tietoja taulukko sisältää. (T3) Lähde on mainittava, jos tiedot ovat peräisin muusta julkaisusta tai aineistosta, jota artikkelissa ei pääsääntöisesti käsitellä. (T4) Jokaisella rivillä ja sarakkeella on tiivis yksikäsitteinen nimi tai otsikko (esim. ikävuosien luokitus 0-15, 15-25, 25-35,... ei ole yksikäsitteinen mutta 0-14, 15-24, 25-34,... on). (T5) Käytetyt mittayksiköt, koodit ja lyhenteet on selvitettävä, tarvittaessa alareunaan sijoitettavissa viitteissä. (T6) Sarakkeiden otsikot ja alaviitteet erotetaan muusta taulukosta vaakasuorin viivoin. Eri hierarkiatasojen sarakeotsikot erotetaan myös toisistaan vaakaviivoin siten, että ylemmän tason otsikon alle tuleva yhtäjaksoinen viiva kattaa vain tälle otsikolle alisteiset sarakkeet. (T7) Sarakkeita ei nykyisin vallitsevan käytännön mukaan erotella pystyviivoilla. Tässä tosin julkaisusarjojen käytännöt hieman vaihtelevat. (T8) Vertailtavat suureet kannattaa sijoittaa mahdollisimman lähelle toisiaan. Lukujen vertailu alekkain on helpompaa kuin rinnakkain, joten jos muut näkökohdat antavat kohtuudella myöten, kiinnostavin luokittelutekijä kannattaa usein sijoittaa sisimmäksi rivimuuttujaksi. (T9) Tyhjiä soluja ei jätetä. Jos tieto puuttuu, se korvataan kahdella pisteellä. Jos lukua ei ole mielekkäästi olemassa (esim. eturauhassyövän tapausmäärä naisilla), merkitään yksi piste. Yhdysviiva tarkoittaa, että ao. lukumäärä tai siihen perustuva suhteellinen osuus on nolla, mutta luku 0 kuvaa arvoa, jonka suuruus on alle puolet pyöristystarkkuudesta (esim. alle 0.5 %). (T10) Taulukoitaessa luokiteltuja muuttujia ristiin prosenttilaskujen suunnan yleisperiaate on se, että esitetään kohde- tai vastemuuttujan arvojen prosenttijakaumat selittävän tai ennustavan muuttujan luokissa, jos otanta-asetelma sallii. Prosenttien nimittäjien täytyy myös näkyä esim. omilla riveillään tai sarakkeillaan (usein suluissa). 20
 Taulukon on oltava mahdollisimman yksinkertainen ja itsensä selittävä. Se on kyettävä ymmärtämään Aineisto ja menetelmät -lukuun perehtymisen jälkeen ilman tukeutumista tekstiin.")
21 (T11) Erityisesti lukumäärä- ja prosenttijakaumien yhteydessä on hyvä laskea näkyviin myös summarivejä ja -sarakkeita. Periaatteessa kaikkien yhteenlaskettavien lukujen tulisi olla näkyvissä, eli myös luokan tieto puuttuu (joskaan tälle luokalle ei aina välttämättä tarvitse varata omaa riviä tai saraketta, kunhan ainakin alaviitteessä ilmaistaan, kuinka moni puuttuvan tiedon omaava havaintoyksikkö sisältyi ao. rivi- tai sarakesummaan). (T12) Taulukon luettavuutta parantaa usein, jos rivit ja sarakkeet järjestetään niiden suuruuden mukaisesti (esim. reunajakaumien, summarivien tai sarakkeiden lukujen perusteella, suurinta lukua vastaava luokka ylimmälle riville tai vasemmanpuolimmaiseksi sarakkeeksi, jne.), ellei luokkien järjestystä täysin määrää painavampi sisällöllinen kriteeri Kuvioesityksiä koskevia suosituksia Hyvien ja informatiivisten tilastollisten kuvien piirtäminen on vielä vaativampi taiteenlaji kuin taulukointi. Kuvaesitysten visuaalinen voima on suuri erityisesti muuttujien välisten yhteyksien, trendien ym. hahmottamisessa, mutta yksi kuva voi helposti valehdella enemmän kuin miljoona sanaa. Datatekniikan kehitys on tuonut jokaisen tutkijan ulottuville helppokäyttöisiä grafiikkaohjelmia, joissa on runsas valikoima yleisimpiä tyyppikuvapohjia. Monet ns. bisnesgrafiikan kuvatyypit ovat kuitenkin tieteelliseltä, tilastolliselta ja havaintopsykologiselta kannalta ala-arvoisia (esim. piirakkakuviot ja monet kolmiulotteisen vaikutelman antavat kuvat). Kuvaesitysten osalta seuraavaa osin lähteistä Tufte (1983), Cleveland (1985), Hakulinen ja Teppo (1988) poimittua ohjelistaa voi pitää minimaalisena. (Em. ohjeet (T1) (T3) ovat suoraan käännettävissä vastaaviksi kuvaohjeiksi.) (K4) Kuvan tyypin valinnassa ja sen yksityiskohtien toteutuksessa kannattaa tähdätä data/muste-suhteen (data/ink ratio) maksimointiin eli käyttää viivaa, symboleita, varjostuksia ym. säästeliäästi olennaisen informaation välittämiseksi. (K5) Kuva-alue täytetään mahdollisimman tehokkaasti. Akselin asteikko ulotetaan hieman ao. muuttujan havaitun vaihteluvälin ulkopuolelle. Tehokas täyttäminen voi joskus vaatia asteikon katkaisua, jota pitää kuitenkin käyttää varoen. (K6) Vaaka- ja pystyakselien kuvaamat suureet mittayksiköineen on nimettävä selvästi. Asteikon jakopisteitä merkitään riittävästi (minimi on kolme) mutta ei liian tiheästi. Havaitun vaihteluvälin ulkopuolisia jakopisteitä on yksi kummallakin puolella. Jakoviivat merkitään kuvaalueesta ulospäin. 21
22 (K7) Lukumääriä, suhteellisia osuuksia ym. ei-negatiivisia suureita kuvaava lineaariasteikko alkaa periaatteessa nollasta (ks. kuitenkin (K5)). (K8) Kuva-alue kannattaa usein kehystää kopioimalla vaaka-akseli alueen yläreunaan ja pystyakseli oikeaan reunaan, jakoviivat edelleen ulospäin. Jomman kumman akselin muutamia tärkeitä viitearvoja voi paikallistaa toisen akselin suuntaisilla ohuilla viivoilla yli koko kuva-alueen. (K9) Käytettävät symbolit, viivatyypit, rasterit, varjostukset, koodit, lyhenteet, tunnukset ym. on selitettävä lyhyesti joko otsikon yhteydessä tai tiiviillä avaimella, joka on selvästi erillään datan täyttämän alueesta. (K10) Eroteltaessa eri luokkia, ryhmiä ym. toisistaan täytyy käyttää hyvin toisistaan erottuvia symboleita, viivoja ym. (K11) Erityisen kriittinen pitää olla kolmiulotteisen vaikutelman antavien kuvien suhteen; niitä ei varsinkaan pidä käyttää silloin, kun kolmas ulottuvuus ei pidä sisällään erillistä sisällöllistä ulottuvuutta eli uutta muuttujaa. 22
23 TILASTOTIETEEN PERUSTEET, kl 2011 Luku 4: TILASTOLLINEN PÄÄTTELY 4.1 Päättelytilanteita ja -kohteita Esim. 1. Eri puolueiden k {kok, sdp, kes, ps, vih, vas, rkp, kd, muu} kannatusosuudet θ k (jossa k θ k = 1 eli 100%) äänestäjäkunnassa tällä hetkellä? Esim. 2. Narkolepsiaan sairastuvien lasten ja nuorten lukumäärän Y k odotusarvo θ k = E(Y k ) vuosina k , k = 1, 2, 3, 4? Poikkeaako vuoden 2010 arvo θ 5 muiden vuosien tasosta ja kuinka paljon? Esim. 3. Miesopiskelijoiden pituuden Y i (i = 1, 2,..., N) jakauman keskitai odotusarvo θ = E(Y i ) ja keskihajonta σ = var(y i ) yliopisto- ja korkeakouluopiskelijain populaatiossa lukuvuonna ? Esim. 4. Flunssaepisodien keskimääräinen kesto (vrk) θ C, jos ottaa säännöllisesti 1 g C-vitamiinilisän joka päivä, ja θ B, jos ei nauti C-vitamiinilisää päivittäin, sekä näiden erotus δ = θ C θ B tai suhteellinen erotus ρ = (θ B θ C )/θ B nuorilla kilpauimareilla? Suureet θ, θ k, θ C, θ B, σ, δ ja ρ ovat tutkijoita kiinnostavia mutta arvoltaan tuntemattomia parametreja. Niiden arvoista halutaan informaatiota asianmukaisen tilastollisen tutkimuksen avulla. Kuvailevia kysymyksiä ovat esim ja esim. 4. on syy-seuraussuhdetta koskeva. 4.2 Päättelyn kysymykset Millainen havaintoaineisto antaisi mahdollisimman luotettavaa (harhatonta ja tarkkaa) informaatiota tuntemattomista parametreista? Mikä on θ:n (θ k :n, jne.) oikea tarkka arvo? Mikä on havaintoaineiston pohjalta paras yksittäinen arvio θ:lle? Onko havaintoaineisto hyvin sopusoinnussa jonkin θ:lle oletetun arvon θ 0 kanssa, vai antaako se näyttöä θ 0 :aa vastaan? Kuinka laaja tai kapea on sellaisten θ:n arvojen joukko, joiden kanssa havainnot ovat hyvin sopusoinnussa? 23
24 Miten parhaiten ennustaa saman populaation jonkin uuden havaintoyksikön saamaa arvoa kohdemuuttujalla? Onko analyysissä sovellettu tilastollinen malli riittävän hyvässä sopusoinnussa havaintojen kanssa? 4.3 Tilastollinen malli Esim. 5. Nastanheitto: Tapahtuma A i = nasta jää selälleen i. heitossa. Heitot i = 1,..., n ovat riippumattomia, kussakin heitossa θ = P(A i ). Olkoon Y i = 1 Ai tapahtuman A i ilmaisin: Y i = 1, kun A i toteutuu, Y i = 0, kun A c i toteutuu. Kunkin Y i todennäköisyysjakauma on Bern(θ). Riippumattomuudesta seuraa, että summa M = n Y i = selälleen päättyneiden lkm n toistossa noudattaa Bin(n, θ)-jakaumaa, jonka pistetodennäköisyydet ovat ( ) n P(M = m; θ) = θ m (1 θ) n m, m = 0, 1,..., n, m odotusarvo E(M) = nθ ja varianssi var(m) = nθ(1 θ). Riittävän suurella n:n arvolla, samalla kun θ ei ole liian lähellä arvoja 0 ja 1, pätee likimääräisesti (sivuuttaen ns. epäjatkuvuuskorjaus) normaaliapproksimaatio: M N(nθ, nθ(1 θ)) eli M/n N(θ, θ(1 θ)/n); ts. ( ) ( ) m nθ m/n θ P(M m) Φ = Φ. nθ(1 θ) θ(1 θ)/n Todennäköisyyslaskennassa lähdetään siitä, että kun n N + ja θ ]0, 1[ ovat arvoltaan tunnettuja, niin satunnaismuuttujan M jakauma on täydellisesti määrätty, ja voidaan tarkasti laskea kaikki piste-tn:t, odotusarvo, varianssi ym. jakaumatunnusten arvot. Esimerkiksi, kun n = 25 ja θ = 0.3, saadaan oheisenlainen pistetodennäköisyyksien P(M = m; 0.3) kuvaaja, odotusarvona ja varianssina E(M) = 7.5 ja var(m) =
25 P(M=m) M ~ Bin(25, 0.3), E(M) = 7.5, var(m) = m Jos edelleen n = 25 mutta nyt θ = 0.6, niin jakauman painopiste siirtyy edelliseen verrattuna oikealle päin, ja odotusarvo ja varianssi ovat E(M) = 15, var(m) = 6. P(M=m) M ~ Bin(25, 0.6), E(M) = 15, var(m) = m Tilastollisessa ongelmassa lähtökohta on se, että tapahtuman A i todennäköisyys θ = P(A i ) on tuntematon. Siitä pyritään hankkimaan informaatiota n toistosta saatavien A i :n havaittujen esiintymisten y 1,..., y n ja niiden summan m ja suhteellisen osuuden p = m/n avulla. Pienellä kirjaimella merkityt suureet ovat vastaavien isokirjaimisten satunnaismuuttujien, kuten M ja M/n, realisaatioita mallin Bin(n, θ) puitteissa. Tilastolliset tehtävät ja kysymykset koskien parametria θ ovat seuraavia (i) Piste-estimointi: Mikä on se θ:n mahdollinen arvo θ, joka parhaiten ennustaisi satunnaismuutujan M havaitun arvon m? (ii) Testaus: Onko havainto M = m riittävän hyvin sopusoinnussa jonkin θ:a koskevan ennalta asetetun nollahypoteesin H 0 : θ = θ 0 (kuten θ 0 = 0.5) kanssa, vai antaako aineisto näyttöä H 0 :a vastaan? 25
26 (iii) Väliestimointi. Mikä on sellainen θ:n mahdollisten arvojen väli [ θ a, θ b ], joiden kanssa havainto M = m on kohtuullisen hyvin sopusoinnussa? 4.4 Uskottavuusfunktio Tilastollisen päättelyn kysymyksiin vastaamisessa lähestymistapa perustuu keskeisesti parametrin θ uskottavuusfunktioon, joka on omaksutun mallin sekä havaintojen määräämä. Jos esim. Bin(n, θ)-mallissa on havaittu M = m, niin uskottavuusfunktiossa L(θ) = L(θ; m) tarkastellaan juuri tämän arvon todennäköisyyttä erilaisilla parametrin arvoilla; ts. ( ) n L(θ) = P(M = m; θ) = θ m (1 θ) n m, m = 0, 1,..., n, m Erotuksena pistetodennäköisyysfunktioon, jossa θ on kiinteä ja tunnettu ja jossa vaihtelevana argumenttina on satunnaismuuttujan M mahdollinen realisaatio, on uskottavuusfunktiossa juuri tämä M:n havaittu arvo m kiinnitetty, mutta vaihtelevana argumenttina on parametri θ. Esim. Olli Opiskelija heitti nastaa n = 25 kertaa, ja selälleen päätyneiden heittojen lukumääräksi hän sai m = 11. Tämän havainnon todennäköisyydet eräillä valituilla θ:n arvoilla olisivat ( ) 25 θ = 0.3 : P(M = 11; 0.3) = (1 0.3) 14 = , 11 ( ) 25 θ = 0.4 : P(M = 11; 0.4) = (1 0.4) 14 = , 11 ( ) 25 θ = 0.5 : P(M = 11; 0.5) = (1 0.5) 14 = , 11 ( ) 25 θ = 0.6 : P(M = 11; 0.6) = (1 0.6) 14 = Kun sama laskelma tehdään jokaiselle mahdolliselle θ:n arvolle 0:n ja 1:n välillä, saadaan jatkuva uskottavuusfunktio L(θ) täysin määrätyksi. Seuraavalla sivulla on ensin neljän edellä käsitellyn binomijakauman Bin(25, θ), θ {0.3, 0.4, 0.5, 0.6} pistetodennäköisyysfunktioiden piikkikuvaajat. Niiden alla on tästä mallista saadun havainnon m = 11 määräämän uskottavuusfunktion kuvaaja. Oikeanpuoleisella y-akselilla on suhteellisen uskottavuusfunktion L(θ)/L( θ) asteikko, jota pääsääntöisesti sovelletaan uskottavuusfunktion tarkasteluissa. 26
27 theta = m theta = theta = m P(M=m) P(M=m) P(M=m) m theta = m P(M=m) theta:n uskottavuus kun m/n=11/ theta L(theta)
28 Uskottavuusfunktio sisältää kaiken informaation, mitä havainnot y 1,..., y n ja summa m kertovat mallin Bin(n, θ) tuntemattomasta parametrista θ. Kuvaajasta voi mm. arvioida, että havaintojen valossa kaikkein uskottavin θ:n arvo on 0.44, joka on uskottavuusfunktion maksimipiste. Lisäksi varsin uskottavia arvoja ovat mm. 0.4 ja 0.5. Sen sijaan mitä kauemmaksi maksimipisteestä 0:n ja 1:n suuntaan edetään, sitä epäuskottavampiin θ:n arvoihin päädytään tällä aineistolla. Huomattakoon, että uskottavuusfunktiota L(θ) ei voi tulkita parametrin θ todennäköisyystiheytenä, eikä sen integroiminen yli koko yksikkövälin tai sen minkään äärellisen osavälin tuota mitään tulkittavissa olevaa funktiota tai lukua. Uskottavuusfunktion logaritmia l(θ) = log L(θ) kutsutaan log-uskottavuusfunktioksi. Se sisältää kaiken saman informaation kuin L(θ) mutta on monissa laskelmissa käyttökelpoisempi. Log-uskottavuusfunktion 1. derivaatta u(θ) = l (θ) on parametrin θ pistemäärä- tai gradienttifunktio, ja 2. derivaatan vastaluku j(θ) = l (θ) on puolestaan informaatiofunktio. Mallin Bin(n, θ) yhteydessä ja havainnon M = m määräämänä näiden funktioiden lausekkeet ovat ( ) n l(θ) = m log(θ) + (n m) log(1 θ) + log, m u(θ) = m θ n m 1 θ = m nθ θ(1 θ), j(θ) = m θ 2 + n m (1 θ) Piste-estimointi Parametrin θ piste-estimaatti on sopiva havaittujen arvojen y 1,..., y n funktio t = t(y 1,..., y n ). Piste-estimaattori on puolestaan vastaava satunnaismuuttuja T = t(y 1,..., Y n ). Estimaattori T on satunnaismuuttuja, jonka vaihtelua mahdollisesta samankokoisesta otoksesta toiseen kuvaa T :n teoreettinen otantajakauma. Tämän otantajakauman toivotaan keskittyvän parametrin oikean arvon θ lähiympäristöön. Ero estimaattorin ja estimaatin välillä on analoginen sen kanssa, mikä on ero muuttujan ja muuttujan arvon välillä. Jos erityisesti otantajakauman odotusarvolle pätee E(T ) = θ, niin estimaattori T on harhaton; muussa tapauksessa harhainen. Lievä harha ei välttämättä ole ongelmallinen, kunhan estimaattori on tarkentuva, mikä tarkoittaa sitä, että havaintomäärän n kasvaessa odotusarvo suppenee kohti θ:a ja otantajakauman varianssi var(t ) suppenee kohti 0:aa. 28
29 Mallipohjaisessa tilastollisessa päättelyssä optimaalinen piste-estimointi perustuu suurimman uskottavuuden menetelmään (su-menetelmä). Se arvo θ, jolle pätee, että L( θ) L(θ ) jokaisella mahdollisella arvolla θ, on parametrin θ suurimman uskottavuuden estimaatti, lyhemmin su-estimaatti tai SUE. Jos uskottavuusfunktio L(θ) täyttää tietyt matemaattiset säännöllisyysehdot, niin sillä on yksikäsitteinen maksimi. Se on samalla log-uskottavuusfunktion maksimi samoin kuin pistemääräfunktion nollakohta. Näin ollen SUE θ on piste, joka on estimointiyhtälön u(θ) = 0 yksikäsitteinen ratkaisu. Bin(n, θ)-mallissa havainnon M = m pohjalta yhtälö u(θ) = 0 toteutuu täsmälleen arvolla θ = m/n eli onnistuneiden toistojen havaittu suhteellinen osuus, joka onkin tässä mallissa θ:n su-estimaatti. Nastanheittoesimerkissämme SUE on siis θ = 11/25 = 0.44, kuten graafisesti voitiin jo havaita. Yksittäisestä havaintosarjasta (y 1,..., y n ) estimoitu θ = θ(y 1,..., y n ) on siis realisaatio vastaavasta satunnaismuuttujasta, jonka arvot vaihtelisivat mahdollisesta samankokoisesta toistokoesarjasta tai otoksesta toiseen. Tätä satunnaismuuttujaa θ = θ(y 1,..., Y n ) kutsutaan θ:n suurimman uskottavuuden estimaattoriksi. Sitä on tapana merkitä samoin kuin yksittäistä estimaattia. Bin(n, θ)-mallissa θ:n su-estimaattori on θ = M/n, jossa siis satunnaismuuttuja M/n on onnistuvien toistojen havaittavissa oleva osuus. Bin(n, θ)-mallissa su-estimaattorin θ = M/n otantajakauma on skaalattu binomijakauma, jonka odotusarvo on E(M/n) = θ ja varianssi on var(m/n) = θ(1 θ)/n. Koska tässä tapauksessa parametrin θ su-estimaattorin odotusarvo on θ itse, on θ harhaton estimaattori θ:lle. Huomataan myös, että SUE:n otantajakauman varianssi lähenee 0:aa kun n kasvaa, joten estimaattorimme on myös tarkentuva. Estimoinnin satunnaisvirhe on siis sitä pienempi mitä suurempi otos on. Keskeisen raja-arvolauseen ansiosta tätä otantajakaumaa on mahdollista approksimoida normaalijakaumalla N(θ, θ(1 θ)/n). Koska θ on edelleen tuntematon, sen estimaattiin θ joudutaan turvautumaan mm. kun lasketaan estimoinnin satunnaisvirheen keskimääräistä suuruutta mittaava estimaattorin keskivirhe (standard error, SE). Tämä tunnusluku on estimaattorin otantajakauman estimoitu keskihajonta eli estimoidun varianssin neliöjuuri: SE(θ) = θ(1 θ)/n. 29
30 4.6 Tilastollinen testaus Tarkastellaan edelleen mallia Bin(n, θ), jossa kiinnostus saattaa kohdistua siihen, onko havaintoaineisto (y 1,..., y n ) ja siitä laskettu SUE θ sopusoinnussa jonkin ennalta asetetun mahdollisen parametrin arvon θ 0 kanssa. Jos todellisuudessa olisi niin, että oletettu θ 0 olisi θ:n oikea arvo, niin seuraava testisuure θ θ 0 Z = θ0 (1 θ 0 )/n, joka on su-estimaattorin θ:n standardoitu muunnos, noudattaisi likimain standardinormaalijakaumaa N(0, 1). Näin ollen, jos siis em. oletus eli nollahypoteesi H 0 : θ = θ 0 pätisi, niin Z:n odotusarvo olisi 0, varianssi ja keskihajonta 1. Edelleen, tässä tilanteessa todennäköisyys saada Z:n arvoja esim. väliltä [ 1, 1], olisi likimain 0.683, ja välille [ 2, 2] osumisen todennäköisyys olisi n Sen sijaan todennäköisyys saada H 0 :n vallitessa itseisarvoltaan suurempia Z:n arvoja kuin 2.5 olisi vain Nastanheitossa kiinnostava nollahypoteesi voisi olla symmetriaoletus eli H 0 : θ = 0.5. Lasketaanpa tällä oletuksella suureen Z toteutunut arvo Z hav, kun heittoja oli n = 25 ja selälleen jääneiden havaittu lukumäärä oli 11, jolloin θ = 0.44: Z hav = = (1 0.5)/25 Todennäköisyys saada havaittua Z:n arvoa itseisarvoltaan vähintään yhtä suuria poikkeamia odotusarvosta 0, on nyt P( Z Z hav ) = P(Z 0.6) + P(Z 0.6) 0.55, mikä on kohtalaisen suuri todennäköisyys. Voi siis päätellä, että havaittu tulos ja piste-estimaatti θ = 0.44 on hyvin sopusoinnussa oletuksen θ = 0.5 kanssa, koska vähintään havaitunsuuruisen poikkeaman todennäköisyys nollahypoteesin vallitessa on näinkin suuri. Tätä todennäköisyyttä P = P( Z z hav ) kutsutaan yleisesti nimellä havaittu merkitsevyystaso eli P-arvo. Sitä käytetään yleisesti mittana havaintoaineiston sisältämän näytön voimakkuudesta nimen omaan nollahypoteesia vastaan: mitä pienempi P, sitä vahvempi on näyttö H 0 :a vastaan. Toisaalta, suuri P, joka viittaa sopusointuun H 0 :n kanssa, ei sellaisenaan vielä tarkoita sitä, että havainnot antaisivat tukevaa näyttöä erityisesti H 0 :n määrittelemän pistearvon θ 0 puolesta. Esimerkiksi nastanheitossa saamamme P-arvo P = 0.55 ei sinänsä tue nollahypoteesia H 0 : θ = 0.5 sen enempää kuin vaikkapa sitä epäsymmetristä 30
31 mahdollisuutta että θ:n arvo olisi Toisaalta havaittu tulos θ = 0.44 ja P = 0.55 eivät tässä tilanteessa eli näin pienellä toistojen määrällä n = 25 myöskään sisällä lähestulkoonkaan riittävää näyttöä symmetriaoletusta θ = 0.5 vastaan. P-arvojen tulkinta ei ole yksikäsitteistä, vaan siinä pitää ottaa huomioon useita tilannekohtaisia seikkoja. Monilla soveltavilla tieteenaloilla on silti edelleen hyvin tavallista, että P-arvoja tulkitaan ajattelematta ja mekaanisesti jonkin mielivaltaisen ennalta asetetun merkitsevyystason kuten 0.05 perusteella tyyliin: Jos P < 0.05, niin tulos on tilastollisesti merkitsevä ja jos taas P 0.05, niin tulos ei ole tilastollisesti merkitsevä. Pahimmillaan jälkimmäinen vaihtoehto tulkitaan usein virheellisesti niin, että H 0 saa havainnoista tukea. Tällä kurssilla pyrimme välttämään tämäntapaisia yksioikoisia tulkintoja P- arvoista. Seuraavassa hyvin karkea ohjenuora: Jos P 0.1, niin aineisto on kohtalaisesti sopusoinnussa H 0 :n kanssa, Jos 0.01 P < 0.1, niin havainnot antavat heikkoa näyttöä H 0 :a vastaan, Jos P < 0.01, niin havainnot antavat näyttöä H 0 :a vastaan, Testitulosten tulkintaan vaikuttavia osin ulkotilastollisia tekijöitä ovat mm. tutkimusasetelma: käytettiinkö kontrolloitua sattumaa eli havaintoaineiston hankinnassa aitoa satunnaisotantaa tai ryhmiin jakamisessa satunnaistusta, joihin testisuureen otantajakauman nimelliset ominaisuudet perustuvat, etukäteen sisällöllisesti tärkeäksi katsottu ero tai poikkeama nollahypoteesin mukaisesta parametrinarvosta, aineiston koko: suurilla n:n arvoilla on suuri todennäköisyys saada pieni P-arvo, vaikka todellinen ero ei olisi sisällöllisesti tärkeä, kun taas n:n ollessa pieni jää P helposti suureksi eikä anna tarpeeksi näyttöä sitä vastaan, vaikka todellisuudessa ero olisikin merkittävä, ilmiötä koskeva taustatieto tai aikaisempi kokemus. Monissa päättelytilanteissa luottamusvälit (ks. seuraava alaluku) ovat huomattavasti informatiivisempia kuin testaaminen ja P-arvot. 4.7 Luottamusväli 31
32 Nyt siirrymme tarkastelemaan ns. virhemarginaalia ja sen määräämistä. Virhemarginaalilla tarkoitetaan parametrin θ luottamusväliä joka lasketaan halutulla luottamustasolla 100(1 α)%, jossa α on pieni todennäköisyystaso. Tavanomaisia luottamustasoja ovat esim. 95% ja 90%, jolloin α on vastaavasti 0.05 tai 0.1. Luottamusvälin CI = [ θ a, θ b ] ala- ja yläraja θ a ja θ b ovat ennen aineiston hankintaa ja mittauksia luonteeltaan satunnaismuuttujia. Niiden arvot vaihtelisivat mahdollisesta samankokoisesta ja samalla tavalla hankitusta satunnaisotoksesta toiseen θ:n otantajakauman määräämällä tavalla siten, että väli CI peittäisi tuntemattoman parametrin θ oikean arvon todennäköisyydellä 1 α. Toteutuneesta havaintoaineistosta (y 1,..., y n ) laskettu luottamusväli on edellä luonnehditun satunnaisvälin realisaatio. Sitä ei voi tulkita frekventistisen tilastotieteen viitekehyksessä seuraavasti: todennäköisyys sille, että laskettu luottamusväli sisältää θ:n oikean arvon, on 1 α. Omaksuttu luottamustaso kuvaa vain luottamusvälin laskentamenetelmän ominaisuutta tuottaa ao. tason mukaisella osuudella oikean parametrin arvon peittäviä välejä, jos otantaa toistettaisiin samalla otoskoolla pitkänä otossarjana. Luottamusväli konstruoidaan tavallisesti vastaavan testisuureen avulla. Nyt kuitenkaan ei kiinnittäydytä yhteen yksittäiseen nolla-arvoon θ 0 ja lasketa vain sille, kuinka suuria ovat vastaava testisuureen arvo ja P-arvo. Sen sijaan kiinnitetään luottamustaso ja sen mukainen α ja haetaan kaikki sellaiset θ:n mahdolliset arvot θ, jotka ovat havaintojen kanssa sopusoinnussa niin, että hypoteesia H : θ = θ vastaava P-arvo on suurempi kuin α. Tämä toteutetaan seuraavalla tavalla. Olkoon θ parametrin θ oikea arvo. Tarkastellaan testisuureen Z = Z(θ ) otantajakaumaa. Vähintään likimääräisesti pätee nyt, että Z(θ ) N(0, 1), jolloin mm. pätee, että P(z α/2 Z(θ ) z 1 α/2 ) = P( Z(θ ) z 1 α/2 ) = 1 α, jossa z u tarkoittaa N(0, 1)-jakauman u-fraktiilia, eli P(Z z u ) = Φ(z u ) = u, jok. u ]0, 1[. Kun esimerkiksi luottamustaso on 95 %, niin α = 0.05 ja z α/2 = z = 1.96, z 1 α/2 = z = Normaalijakauman symmetrisyyden ansiosta em. todennäköisyys voidaan kirjoittaa myös muotoon P( Z(θ ) z 1 α/2 ) = P(Z(θ ) 2 z 2 1 α/2) = 1 α. Nyt tehtävänä on ratkaista 2. asteen epäyhtälö Z(θ ) 2 z 2 1 α/2 tuntemattoman argumentin θ suhteen, ja ratkaisuksi saadaan haluttu luottamusväli [ θ a, θ b ]. 32
33 Bin(n, θ)-mallissa tätä periaatetta sovellettaessa päädytään epäyhtälöön Z(θ ) 2 = ( θ θ ) 2 θ (1 θ )/n z2 1 α/2 Tämän epäyhtälön tarkka ratkaisu (harjoitustehtävä!) tuottaa ns. Wilsonin luottamusvälin parametrille θ. Sen ala- ja ylärajat määrittelevä tarkka lauseke on kuitenkin tarpeettoman mutkikas. Erittäin hyvän likiarvoisen ratkaisun em. epäyhtälölle tarjoaa seuraava Agrestin ja Coullin esittämä AC-luottamusväli. Lasketaan ensin piste-estimaatin ja keskivirheen muokatut arvot θ = M + 2 n + 4, SE( θ) = θ(1 θ) n + 4. Tämän jälkeen luottamusvälin ala- ja yläraja määräytyvät kaavoista θ a = θ z 1 α/2 SE( θ), θb = θ + z 1 α/2 SE( θ). Kaikkein yksinkertaisin ja edelleen ylivoimaisesti suosituin tapa laskea likimääräinen luottamusväli Bin(n, θ)-mallin parametrille θ perustuu muokkaamattomaan estimaattiin θ ja sen keskivirheeseen SE( θ) = θ(1 θ)/n, joiden mukaiset rajat määräytyvät kaavasta θ ± z 1 α/2 SE( θ). Pienillä otoksilla ja θ:n arvon ollessa lähellä 0:aa tai 1:tä, tämä kaava saattaa johtaa yli laitojen meneviin epäloogisiin väleihin; ts. joko alaraja on negatiivinen tai yläraja on suurempi kuin 1. Nastanheittoesimerkissämme, jossa n = 25 ja havaittiin θ = 11/25 = 0.44, saadaan muokattujen suureiden arvoiksi θ = = , SE( θ) = joiden pohjalta 95% AC-luottamusväli on ( ) 29 = , ± = [0.2673, ]. Tavanomaisella kaavalla laskettu keskivirhe on SE( θ) = ja siitä luottamusväliksi tulee 0.44(1 0.44) 25 = ± = [0.2454, ]. 33
34 Tässä tapauksessa, kun piste-estimaatti on lähellä arvoa 0.5, erot eri menetelmien tuottamien välien kesken eivät ole olennaisia. Lisätietoja binomimallin parametrin erilaisista luottamusväleistä ks. esim Kahden riippumattoman otoksen vertailu Yksittäisten populaatioiden parametrit ovat joissakin erikoistilanteissa riittävän kiinnostavia niin, että on hyödyllistä estimoida niitä ja laskea niille luottamusvälejä, ehkä jopa testata relevantteja nollahypoteeseja. Useimmat kiinnostavat tutkimuskysymykset ovat kuitenkin vertailevia. Esim. 1. (jatkuu). Puolueen k kannatusosuutta tällä hetkellä halutaan usein verrata vaikkapa puolta vuotta aikaisempaan kannatusosuuteen. Kysymys asetetaan esimerkiksi, onko näyttöä siitä, että kannatusosuudessa olisi tapahtunut jotain muutosta ajankohtien välillä ja mihin suuntaan? Vähintään yhtä mielenkiintoista on tietää kannatusosuuksien mahdollisista eroista eri puolueiden välillä samana ajankohtana. Ensimmäisessä tilanteessa vastauksen hakeminen perustuu äänestäjäkunnasta eri ajankohtina poimittuihin otoksiin, joita voidaan pitää toisistaan riippumattomina. Eri puolueiden vertailu saman otoksen sisällä puolestaan merkitsee sitä, että havaittavat kannatusosuudet M k /n ovat toisistaan tilastollisesti riippuvat, koska osuuksien summaa yli kaikkien puolueiden sitoo lineaarinen riippuvuus: k M/k = 1 eli 100%. Tämä riippuvuus pitää asianmukaisesti ottaa huomioon osuuksien erotuksen virhemarginaalia laskettaessa. Kahden riippumattoman toistokokeen vertailuun kohdistuva malli rakennetaan seuraavasti. Olkoot M 1 ja M 2 toisistaan riippumattomia satunnaismuuttujia, jotka kuvaavat onnistuneiden tulosten lukumääriä kahdessa eri toistokoetilanteessa, joissa onnistumistodennäköisyydet θ 1 ja θ 2 voivat olla erilaiset samoin kuin toistojen määrät eli otoskoot n 1 ja n 2. Nyt oletamme, että kummallekin j = 1, 2 pätee M j Bin(n j, θ j ), ja lisäksi M 1 M 2. Kiinnostavana vertailuparametrina tarkastelemme todennäköisyyksien erotusta δ = θ 1 θ 2. Toisinaan todennäköisyyksien vertailuparametreina käytetään myös suhdetta φ = θ 1 /θ 2 ja vetosuhdetta φ = [θ 1 /(1 θ 1 )]/[θ 2 /(1 θ 2 )] Riippumattomuudesta ja muista mallioletuksista sekä normaalijakautuneiden satunnaismuuttujien summaa koskevista jakaumatuloksista seuraa suoraviivaisesti, että θ 1 :n ja θ 2 :n su-estimaattorit ovat θ j toisistaan riippumattomat, = M j /n j, j = 1, 2, ja ne ovat 34
Tilastotieteen kertaus. Kuusinen/Heliövaara 1
 Tilastotieteen kertaus Kuusinen/Heliövaara 1 Mitä tilastotiede on? Tilastotiede kehittää ja soveltaa menetelmiä, joiden avulla reaalimaailman ilmiöistä voidaan tehdä johtopäätöksiä tilanteissa, joissa
Tilastotieteen kertaus Kuusinen/Heliövaara 1 Mitä tilastotiede on? Tilastotiede kehittää ja soveltaa menetelmiä, joiden avulla reaalimaailman ilmiöistä voidaan tehdä johtopäätöksiä tilanteissa, joissa
tilastotieteen kertaus
 tilastotieteen kertaus Keskiviikon 24.1. harjoitukset pidetään poikkeuksellisesti klo 14-16 luokassa Y228. Heliövaara 1 Mitä tilastotiede on? Tilastotiede kehittää ja soveltaa menetelmiä, joiden avulla
tilastotieteen kertaus Keskiviikon 24.1. harjoitukset pidetään poikkeuksellisesti klo 14-16 luokassa Y228. Heliövaara 1 Mitä tilastotiede on? Tilastotiede kehittää ja soveltaa menetelmiä, joiden avulla
TUTKIMUSAINEISTON KVANTITATIIVINEN ANALYYSI LTKY012. Timo Törmäkangas
 TUTKIMUSAINEISTON KVANTITATIIVINEN ANALYYSI LTKY012 Timo Törmäkangas TEOREETTISISTA JAKAUMISTA Usein johtopäätösten teko helpottuu huomattavasti, jos tarkasteltavan muuttujan perusjoukon jakauma noudattaa
TUTKIMUSAINEISTON KVANTITATIIVINEN ANALYYSI LTKY012 Timo Törmäkangas TEOREETTISISTA JAKAUMISTA Usein johtopäätösten teko helpottuu huomattavasti, jos tarkasteltavan muuttujan perusjoukon jakauma noudattaa
Tilastotieteen kertaus. Vilkkumaa / Kuusinen 1
 Tilastotieteen kertaus Vilkkumaa / Kuusinen 1 Motivointi Reaalimaailman ilmiöihin liittyy tyypillisesti satunnaisuutta ja epävarmuutta Ilmiöihin liittyvien havaintojen ajatellaan usein olevan peräisin
Tilastotieteen kertaus Vilkkumaa / Kuusinen 1 Motivointi Reaalimaailman ilmiöihin liittyy tyypillisesti satunnaisuutta ja epävarmuutta Ilmiöihin liittyvien havaintojen ajatellaan usein olevan peräisin
Estimointi. Vilkkumaa / Kuusinen 1
 Estimointi Vilkkumaa / Kuusinen 1 Motivointi Tilastollisessa tutkimuksessa oletetaan jonkin jakauman generoineen tutkimuksen kohteena olevaa ilmiötä koskevat havainnot Tämän mallina käytettävän todennäköisyysjakauman
Estimointi Vilkkumaa / Kuusinen 1 Motivointi Tilastollisessa tutkimuksessa oletetaan jonkin jakauman generoineen tutkimuksen kohteena olevaa ilmiötä koskevat havainnot Tämän mallina käytettävän todennäköisyysjakauman
Hannu mies LTK 180 Johanna nainen HuTK 168 Laura nainen LuTK 173 Jere mies NA 173 Riitta nainen LTK 164
 86118P JOHDATUS TILASTOTIETEESEEN Harjoituksen 3 ratkaisut, viikko 5, kevät 19 1. a) Havaintomatriisissa on viisi riviä (eli tilastoyksikköä) ja neljä saraketta (eli muuttujaa). Hannu mies LTK 18 Johanna
86118P JOHDATUS TILASTOTIETEESEEN Harjoituksen 3 ratkaisut, viikko 5, kevät 19 1. a) Havaintomatriisissa on viisi riviä (eli tilastoyksikköä) ja neljä saraketta (eli muuttujaa). Hannu mies LTK 18 Johanna
Johdatus tilastotieteeseen Estimointi. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus tilastotieteeseen Estimointi TKK (c) Ilkka Mellin (2005) 1 Estimointi Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin ominaisuudet TKK (c) Ilkka Mellin (2005) 2 Estimointi:
Johdatus tilastotieteeseen Estimointi TKK (c) Ilkka Mellin (2005) 1 Estimointi Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin ominaisuudet TKK (c) Ilkka Mellin (2005) 2 Estimointi:
Til.yks. x y z
 Tehtävien ratkaisuja. a) Tilastoyksiköitä ovat työntekijät: Vatanen, Virtanen, Virtanen ja Voutilainen; muuttujina: ikä, asema, palkka, lasten lkm (ja nimikin voidaan tulkita muuttujaksi, jos niin halutaan)
Tehtävien ratkaisuja. a) Tilastoyksiköitä ovat työntekijät: Vatanen, Virtanen, Virtanen ja Voutilainen; muuttujina: ikä, asema, palkka, lasten lkm (ja nimikin voidaan tulkita muuttujaksi, jos niin halutaan)
Estimointi. Estimointi. Estimointi: Mitä opimme? 2/4. Estimointi: Mitä opimme? 1/4. Estimointi: Mitä opimme? 3/4. Estimointi: Mitä opimme?
 TKK (c) Ilkka Mellin (2004) 1 Johdatus tilastotieteeseen TKK (c) Ilkka Mellin (2004) 2 Mitä opimme? 1/4 Tilastollisen tutkimuksen tavoitteena on tehdä johtopäätöksiä prosesseista, jotka generoivat reaalimaailman
TKK (c) Ilkka Mellin (2004) 1 Johdatus tilastotieteeseen TKK (c) Ilkka Mellin (2004) 2 Mitä opimme? 1/4 Tilastollisen tutkimuksen tavoitteena on tehdä johtopäätöksiä prosesseista, jotka generoivat reaalimaailman
Testejä suhdeasteikollisille muuttujille
 Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Testejä suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (007) 1 Testejä suhdeasteikollisille muuttujille >> Testit normaalijakauman
Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Testejä suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (007) 1 Testejä suhdeasteikollisille muuttujille >> Testit normaalijakauman
pisteet Frekvenssi frekvenssi Yhteensä
 806118P JOHDATUS TILASTOTIETEESEEN Loppukoe 15.3.2018 (Jari Päkkilä) 1. Kevään -17 Johdaus tilastotieteeseen -kurssin opiskelijoiden harjoitusaktiivisuudesta saatujen pisteiden frekvenssijakauma: Harjoitus-
806118P JOHDATUS TILASTOTIETEESEEN Loppukoe 15.3.2018 (Jari Päkkilä) 1. Kevään -17 Johdaus tilastotieteeseen -kurssin opiskelijoiden harjoitusaktiivisuudesta saatujen pisteiden frekvenssijakauma: Harjoitus-
Tilastollisen analyysin perusteet Luento 1: Lokaatio ja hajonta
 Tilastollisen analyysin perusteet Luento 1: ja hajonta Sisältö Havaittujen arvojen jakauma Havaittujen arvojen jakaumaa voidaan kuvailla ja esitellä tiivistämällä havaintoarvot sopivaan muotoon. Jakauman
Tilastollisen analyysin perusteet Luento 1: ja hajonta Sisältö Havaittujen arvojen jakauma Havaittujen arvojen jakaumaa voidaan kuvailla ja esitellä tiivistämällä havaintoarvot sopivaan muotoon. Jakauman
Osa 2: Otokset, otosjakaumat ja estimointi
 Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi TKK (c) Ilkka Mellin (2007) 1 Estimointi >> Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin
Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi TKK (c) Ilkka Mellin (2007) 1 Estimointi >> Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin
Harjoitus 2: Matlab - Statistical Toolbox
 Harjoitus 2: Matlab - Statistical Toolbox Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen tavoitteet Satunnaismuuttujat ja todennäköisyysjakaumat
Harjoitus 2: Matlab - Statistical Toolbox Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen tavoitteet Satunnaismuuttujat ja todennäköisyysjakaumat
TUTKIMUSAINEISTON ANALYYSI. LTKY012 Timo Törmäkangas
 TUTKIMUSAINEISTON ANALYYSI LTKY012 Timo Törmäkangas JAKAUMAN MUOTO Vinous, skew (g 1, γ 1 ) Kertoo jakauman symmetrisyydestä Vertailuarvona on nolla, joka vastaa symmetristä jakaumaa (mm. normaalijakauma)
TUTKIMUSAINEISTON ANALYYSI LTKY012 Timo Törmäkangas JAKAUMAN MUOTO Vinous, skew (g 1, γ 1 ) Kertoo jakauman symmetrisyydestä Vertailuarvona on nolla, joka vastaa symmetristä jakaumaa (mm. normaalijakauma)
Tilastollinen testaus. Vilkkumaa / Kuusinen 1
 Tilastollinen testaus Vilkkumaa / Kuusinen 1 Motivointi Viime luennolla: havainnot generoineen jakauman muoto on usein tunnettu, mutta parametrit tulee estimoida Joskus parametreista on perusteltua esittää
Tilastollinen testaus Vilkkumaa / Kuusinen 1 Motivointi Viime luennolla: havainnot generoineen jakauman muoto on usein tunnettu, mutta parametrit tulee estimoida Joskus parametreista on perusteltua esittää
Testit laatueroasteikollisille muuttujille
 Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Testit laatueroasteikollisille muuttujille TKK (c) Ilkka Mellin (2007) 1 Testit laatueroasteikollisille muuttujille >> Laatueroasteikollisten
Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Testit laatueroasteikollisille muuttujille TKK (c) Ilkka Mellin (2007) 1 Testit laatueroasteikollisille muuttujille >> Laatueroasteikollisten
Johdatus tilastotieteeseen Testit laatueroasteikollisille muuttujille. TKK (c) Ilkka Mellin (2004) 1
 Ilkka Mellin (2004) 1") Johdatus tilastotieteeseen Testit laatueroasteikollisille muuttujille TKK (c) Ilkka Mellin (2004) 1 Testit laatueroasteikollisille muuttujille Laatueroasteikollisten muuttujien testit Testi suhteelliselle
Johdatus tilastotieteeseen Testit laatueroasteikollisille muuttujille TKK (c) Ilkka Mellin (2004) 1 Testit laatueroasteikollisille muuttujille Laatueroasteikollisten muuttujien testit Testi suhteelliselle
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 18. lokakuuta 2007 Antti Rasila () TodB 18. lokakuuta 2007 1 / 19 1 Tilastollinen aineisto 2 Tilastollinen malli Yksinkertainen satunnaisotos 3 Otostunnusluvut
Sovellettu todennäköisyyslaskenta B Antti Rasila 18. lokakuuta 2007 Antti Rasila () TodB 18. lokakuuta 2007 1 / 19 1 Tilastollinen aineisto 2 Tilastollinen malli Yksinkertainen satunnaisotos 3 Otostunnusluvut
Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi
 Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi TKK (c) Ilkka Mellin (2006) 1 Estimointi >> Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin
Ilkka Mellin Tilastolliset menetelmät Osa 2: Otokset, otosjakaumat ja estimointi Estimointi TKK (c) Ilkka Mellin (2006) 1 Estimointi >> Todennäköisyysjakaumien parametrit ja niiden estimointi Hyvän estimaattorin
Väliestimointi (jatkoa) Heliövaara 1
 Heliövaara 1") Väliestimointi (jatkoa) Heliövaara 1 Bernoulli-jakauman odotusarvon luottamusväli 1/2 Olkoon havainnot X 1,..., X n yksinkertainen satunnaisotos Bernoulli-jakaumasta parametrilla p. Eli X Bernoulli(p).
Väliestimointi (jatkoa) Heliövaara 1 Bernoulli-jakauman odotusarvon luottamusväli 1/2 Olkoon havainnot X 1,..., X n yksinkertainen satunnaisotos Bernoulli-jakaumasta parametrilla p. Eli X Bernoulli(p).
Johdatus tilastotieteeseen Tilastollisten aineistojen kuvaaminen. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus tilastotieteeseen Tilastollisten aineistojen kuvaaminen TKK (c) Ilkka Mellin (2005) 1 Tilastollisten aineistojen kuvaaminen Havaintoarvojen jakauma Tunnusluvut Suhdeasteikollisten muuttujien tunnusluvut
Johdatus tilastotieteeseen Tilastollisten aineistojen kuvaaminen TKK (c) Ilkka Mellin (2005) 1 Tilastollisten aineistojen kuvaaminen Havaintoarvojen jakauma Tunnusluvut Suhdeasteikollisten muuttujien tunnusluvut
Testit järjestysasteikollisille muuttujille
 Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Testit järjestysasteikollisille muuttujille TKK (c) Ilkka Mellin (2007) 1 Testit järjestysasteikollisille muuttujille >> Järjestysasteikollisten
Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Testit järjestysasteikollisille muuttujille TKK (c) Ilkka Mellin (2007) 1 Testit järjestysasteikollisille muuttujille >> Järjestysasteikollisten
Tilastollisten aineistojen kuvaaminen
 Ilkka Mellin Tilastolliset menetelmät Osa 1: Johdanto Tilastollisten aineistojen kuvaaminen TKK (c) Ilkka Mellin (2007) 1 Tilastollisten aineistojen kuvaaminen >> Havaintoarvojen jakauma Tunnusluvut Suhdeasteikollisten
Ilkka Mellin Tilastolliset menetelmät Osa 1: Johdanto Tilastollisten aineistojen kuvaaminen TKK (c) Ilkka Mellin (2007) 1 Tilastollisten aineistojen kuvaaminen >> Havaintoarvojen jakauma Tunnusluvut Suhdeasteikollisten
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 30. lokakuuta 2007 Antti Rasila () TodB 30. lokakuuta 2007 1 / 23 1 Otos ja otosjakaumat (jatkoa) Frekvenssi ja suhteellinen frekvenssi Frekvenssien odotusarvo
Sovellettu todennäköisyyslaskenta B Antti Rasila 30. lokakuuta 2007 Antti Rasila () TodB 30. lokakuuta 2007 1 / 23 1 Otos ja otosjakaumat (jatkoa) Frekvenssi ja suhteellinen frekvenssi Frekvenssien odotusarvo
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 11. lokakuuta 2007 Antti Rasila () TodB 11. lokakuuta 2007 1 / 15 1 Johdantoa tilastotieteeseen Peruskäsitteitä Tilastollisen kuvailun ja päättelyn menetelmiä
Sovellettu todennäköisyyslaskenta B Antti Rasila 11. lokakuuta 2007 Antti Rasila () TodB 11. lokakuuta 2007 1 / 15 1 Johdantoa tilastotieteeseen Peruskäsitteitä Tilastollisen kuvailun ja päättelyn menetelmiä
Ilkka Mellin Tilastolliset menetelmät. Osa 3: Tilastolliset testit. Tilastollinen testaus. TKK (c) Ilkka Mellin (2007) 1
 Ilkka Mellin (2007) 1") Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Tilastollinen testaus TKK (c) Ilkka Mellin (2007) 1 Tilastolliset testit >> Tilastollinen testaus Tilastolliset hypoteesit Tilastolliset
Ilkka Mellin Tilastolliset menetelmät Osa 3: Tilastolliset testit Tilastollinen testaus TKK (c) Ilkka Mellin (2007) 1 Tilastolliset testit >> Tilastollinen testaus Tilastolliset hypoteesit Tilastolliset
Mat Tilastollisen analyysin perusteet, kevät 2007
 Mat-2.2104 Tilastollisen analyysin perusteet, kevät 2007 4. luento: Jakaumaoletuksien testaaminen Kai Virtanen 1 Jakaumaoletuksien testaamiseen soveltuvat testit χ 2 -yhteensopivuustesti yksi otos otoksen
Mat-2.2104 Tilastollisen analyysin perusteet, kevät 2007 4. luento: Jakaumaoletuksien testaaminen Kai Virtanen 1 Jakaumaoletuksien testaamiseen soveltuvat testit χ 2 -yhteensopivuustesti yksi otos otoksen
805306A Johdatus monimuuttujamenetelmiin, 5 op
 monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Lineaarinen erotteluanalyysi (LDA, Linear discriminant analysis) Erotteluanalyysin avulla pyritään muodostamaan selittävistä muuttujista
monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Lineaarinen erotteluanalyysi (LDA, Linear discriminant analysis) Erotteluanalyysin avulla pyritään muodostamaan selittävistä muuttujista
Jatkuvat satunnaismuuttujat
 Jatkuvat satunnaismuuttujat Satunnaismuuttuja on jatkuva jos se voi ainakin periaatteessa saada kaikkia mahdollisia reaalilukuarvoja ainakin tietyltä väliltä. Täytyy ymmärtää, että tällä ei ole mitään
Jatkuvat satunnaismuuttujat Satunnaismuuttuja on jatkuva jos se voi ainakin periaatteessa saada kaikkia mahdollisia reaalilukuarvoja ainakin tietyltä väliltä. Täytyy ymmärtää, että tällä ei ole mitään
Johdatus todennäköisyyslaskentaan Normaalijakaumasta johdettuja jakaumia. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus todennäköisyyslaskentaan Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2005) 1 Normaalijakaumasta johdettuja jakaumia Johdanto χ 2 -jakauma F-jakauma t-jakauma TKK (c) Ilkka Mellin
Johdatus todennäköisyyslaskentaan Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2005) 1 Normaalijakaumasta johdettuja jakaumia Johdanto χ 2 -jakauma F-jakauma t-jakauma TKK (c) Ilkka Mellin
TUTKIMUSAINEISTON ANALYYSI. LTKY012 Timo Törmäkangas
 TUTKIMUSAINEISTON ANALYYSI LTKY012 Timo Törmäkangas KURSSIN SISÄLTÖ Johdanto Mittaaminen ja aineiston hankinta Mitta-asteikot Otanta Aineiston esittäminen ja data-analyysi Havaintomatriisi Yksiulotteisen
TUTKIMUSAINEISTON ANALYYSI LTKY012 Timo Törmäkangas KURSSIN SISÄLTÖ Johdanto Mittaaminen ja aineiston hankinta Mitta-asteikot Otanta Aineiston esittäminen ja data-analyysi Havaintomatriisi Yksiulotteisen
Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille. TKK (c) Ilkka Mellin (2004) 1
 Ilkka Mellin (2004) 1") Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (004) 1 Testit suhdeasteikollisille muuttujille Testit normaalijakauman parametreille Yhden otoksen t-testi Kahden
Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (004) 1 Testit suhdeasteikollisille muuttujille Testit normaalijakauman parametreille Yhden otoksen t-testi Kahden
Juuri 10 Tehtävien ratkaisut Kustannusosakeyhtiö Otava päivitetty
 Juuri 0 Tehtävien ratkaisut Kustannusosakeyhtiö Otava päivitetty 9..08 Kertaus K. a) Alapaineiden pienin arvo on ja suurin arvo 74, joten vaihteluväli on [, 74]. b) Alapaineiden keskiarvo on 6676870774
Juuri 0 Tehtävien ratkaisut Kustannusosakeyhtiö Otava päivitetty 9..08 Kertaus K. a) Alapaineiden pienin arvo on ja suurin arvo 74, joten vaihteluväli on [, 74]. b) Alapaineiden keskiarvo on 6676870774
Mat Tilastollisen analyysin perusteet, kevät 2007
 Mat-.04 Tilastollisen analyysin perusteet, kevät 007 4. luento: Jakaumaoletuksien testaaminen Kai Virtanen Jakaumaoletuksien testaamiseen soveltuvat testit χ -yhteensopivuustesti yksi otos otoksen vertaaminen
Mat-.04 Tilastollisen analyysin perusteet, kevät 007 4. luento: Jakaumaoletuksien testaaminen Kai Virtanen Jakaumaoletuksien testaamiseen soveltuvat testit χ -yhteensopivuustesti yksi otos otoksen vertaaminen
Tilastollisen analyysin perusteet Luento 1: Lokaatio ja hajonta
 Tilastollisen analyysin perusteet Luento 1: ja hajonta Sisältö Havaittujen arvojen jakauma Havaittujen arvojen jakaumaa voidaan kuvailla ja esitellä tiivistämällä havaintoarvot sopivaan muotoon. Jakauman
Tilastollisen analyysin perusteet Luento 1: ja hajonta Sisältö Havaittujen arvojen jakauma Havaittujen arvojen jakaumaa voidaan kuvailla ja esitellä tiivistämällä havaintoarvot sopivaan muotoon. Jakauman
Mat Tilastollisen analyysin perusteet. Tilastollisten aineistojen kerääminen ja mittaaminen Tilastollisten aineistojen kuvaaminen Väliestimointi
 Mat-2.104 Tilastollisen analyysin perusteet / Ratkaisut Aiheet: Avainsanat: Tilastollisten aineistojen kerääminen ja mittaaminen Tilastollisten aineistojen kuvaaminen Väliestimointi Diskreetit muuttujat,
Mat-2.104 Tilastollisen analyysin perusteet / Ratkaisut Aiheet: Avainsanat: Tilastollisten aineistojen kerääminen ja mittaaminen Tilastollisten aineistojen kuvaaminen Väliestimointi Diskreetit muuttujat,
Til.yks. x y z 1 2 1 20.3 2 2 1 23.5 9 2 1 4.7 10 2 2 6.2 11 2 2 15.6 17 2 2 23.4 18 1 1 12.5 19 1 1 7.8 24 1 1 9.4 25 1 2 28.1 26 1 2-6.2 33 1 2 33.
 Tehtävien ratkaisuja. a) Tilastoyksiköitä ovat työntekijät: Vatanen, Virtanen, Virtanen ja Voutilainen; muuttujina: ikä, asema, palkka, lasten lkm (ja nimikin voidaan tulkita muuttujaksi, jos niin halutaan)
Tehtävien ratkaisuja. a) Tilastoyksiköitä ovat työntekijät: Vatanen, Virtanen, Virtanen ja Voutilainen; muuttujina: ikä, asema, palkka, lasten lkm (ja nimikin voidaan tulkita muuttujaksi, jos niin halutaan)
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 16. marraskuuta 2007 Antti Rasila () TodB 16. marraskuuta 2007 1 / 15 1 Epäparametrisia testejä χ 2 -yhteensopivuustesti Homogeenisuuden testaaminen Antti
Sovellettu todennäköisyyslaskenta B Antti Rasila 16. marraskuuta 2007 Antti Rasila () TodB 16. marraskuuta 2007 1 / 15 1 Epäparametrisia testejä χ 2 -yhteensopivuustesti Homogeenisuuden testaaminen Antti
Mat Tilastollisen analyysin perusteet, kevät 2007
 Mat-2.2104 Tilastollisen analyysin perusteet, kevät 2007 2. luento: Tilastolliset testit Kai Virtanen 1 Tilastollinen testaus Tutkimuksen kohteena olevasta perusjoukosta esitetään väitteitä oletuksia joita
Mat-2.2104 Tilastollisen analyysin perusteet, kevät 2007 2. luento: Tilastolliset testit Kai Virtanen 1 Tilastollinen testaus Tutkimuksen kohteena olevasta perusjoukosta esitetään väitteitä oletuksia joita
1.Työpaikan työntekijöistä laaditussa taulukossa oli mm. seuraavat rivit ja sarakkeet
 VAASAN YLIOPISTO/KESÄYLIOPISTO TILASTOTIETEEN PERUSTEET Harjoituksia A KURSSIKYSELYAINEISTO: 1.Työpaikan työntekijöistä laaditussa taulukossa oli mm. seuraavat rivit ja sarakkeet Nimi Ikä v. Asema Palkka
VAASAN YLIOPISTO/KESÄYLIOPISTO TILASTOTIETEEN PERUSTEET Harjoituksia A KURSSIKYSELYAINEISTO: 1.Työpaikan työntekijöistä laaditussa taulukossa oli mm. seuraavat rivit ja sarakkeet Nimi Ikä v. Asema Palkka
1. Työpaikan työntekijöistä laaditussa taulukossa oli mm. seuraavat rivit ja sarakkeet
 VAASAN YLIOPISTO/AVOIN YLIOPISTO TILASTOTIETEEN PERUSTEET Harjoituksia 1 KURSSIKYSELYAINEISTO: 1. Työpaikan työntekijöistä laaditussa taulukossa oli mm. seuraavat rivit ja sarakkeet Nimi Ikä v. Asema Palkka
VAASAN YLIOPISTO/AVOIN YLIOPISTO TILASTOTIETEEN PERUSTEET Harjoituksia 1 KURSSIKYSELYAINEISTO: 1. Työpaikan työntekijöistä laaditussa taulukossa oli mm. seuraavat rivit ja sarakkeet Nimi Ikä v. Asema Palkka
MTTTA1 Tilastomenetelmien perusteet 5 op Luento Kokonaisuudet johon opintojakso kuuluu
 10.1.2019/1 MTTTA1 Tilastomenetelmien perusteet 5 op Luento 10.1.2019 1 Kokonaisuudet johon opintojakso kuuluu https://www10.uta.fi/opas/opintojakso.htm?rid=14600 &idx=1&uilang=fi&lang=fi&lvv=2018 10.1.2019/2
10.1.2019/1 MTTTA1 Tilastomenetelmien perusteet 5 op Luento 10.1.2019 1 Kokonaisuudet johon opintojakso kuuluu https://www10.uta.fi/opas/opintojakso.htm?rid=14600 &idx=1&uilang=fi&lang=fi&lvv=2018 10.1.2019/2
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 8. marraskuuta 2007 Antti Rasila () TodB 8. marraskuuta 2007 1 / 18 1 Kertausta: momenttimenetelmä ja suurimman uskottavuuden menetelmä 2 Tilastollinen
Sovellettu todennäköisyyslaskenta B Antti Rasila 8. marraskuuta 2007 Antti Rasila () TodB 8. marraskuuta 2007 1 / 18 1 Kertausta: momenttimenetelmä ja suurimman uskottavuuden menetelmä 2 Tilastollinen
Tilastollinen aineisto Luottamusväli
 Tilastollinen aineisto Luottamusväli Keijo Ruotsalainen Oulun yliopisto, Teknillinen tiedekunta Matematiikan jaos Tilastollinen aineisto p.1/20 Johdanto Kokeellisessa tutkimuksessa tutkittavien suureiden
Tilastollinen aineisto Luottamusväli Keijo Ruotsalainen Oulun yliopisto, Teknillinen tiedekunta Matematiikan jaos Tilastollinen aineisto p.1/20 Johdanto Kokeellisessa tutkimuksessa tutkittavien suureiden
Harjoitus 7: NCSS - Tilastollinen analyysi
 Harjoitus 7: NCSS - Tilastollinen analyysi Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen aiheita Tilastollinen testaus Testaukseen
Harjoitus 7: NCSS - Tilastollinen analyysi Mat-2.2107 Sovelletun matematiikan tietokonetyöt Syksy 2006 Mat-2.2107 Sovelletun matematiikan tietokonetyöt 1 Harjoituksen aiheita Tilastollinen testaus Testaukseen
Kandidaatintutkielman aineistonhankinta ja analyysi
 Kandidaatintutkielman aineistonhankinta ja analyysi Anna-Kaisa Ylitalo M 315, anna-kaisa.ylitalo@jyu.fi Musiikin, taiteen ja kulttuurin tutkimuksen laitos Jyväskylän yliopisto 2018 2 Havaintomatriisi Havaintomatriisi
Kandidaatintutkielman aineistonhankinta ja analyysi Anna-Kaisa Ylitalo M 315, anna-kaisa.ylitalo@jyu.fi Musiikin, taiteen ja kulttuurin tutkimuksen laitos Jyväskylän yliopisto 2018 2 Havaintomatriisi Havaintomatriisi
MTTTA1 Tilastomenetelmien perusteet 5 op Luento , osa 1. 1 Kokonaisuudet johon opintojakso kuuluu
 5.3.2018/1 MTTTA1 Tilastomenetelmien perusteet 5 op Luento 5.3.2018, osa 1 1 Kokonaisuudet johon opintojakso kuuluu https://www10.uta.fi/opas/opintojakso.htm?rid=14600 &idx=1&uilang=fi&lang=fi&lvv=2017
5.3.2018/1 MTTTA1 Tilastomenetelmien perusteet 5 op Luento 5.3.2018, osa 1 1 Kokonaisuudet johon opintojakso kuuluu https://www10.uta.fi/opas/opintojakso.htm?rid=14600 &idx=1&uilang=fi&lang=fi&lvv=2017
Johdatus tilastotieteeseen Väliestimointi. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus tilastotieteeseen Väliestimointi TKK (c) Ilkka Mellin (2005) 1 Väliestimointi Todennäköisyysjakaumien parametrien estimointi Luottamusväli Normaalijakauman odotusarvon luottamusväli Normaalijakauman
Johdatus tilastotieteeseen Väliestimointi TKK (c) Ilkka Mellin (2005) 1 Väliestimointi Todennäköisyysjakaumien parametrien estimointi Luottamusväli Normaalijakauman odotusarvon luottamusväli Normaalijakauman
Metsämuuronen: Tilastollisen kuvauksen perusteet ESIPUHE... 4 SISÄLLYSLUETTELO... 6 1. METODOLOGIAN PERUSTEIDEN KERTAUSTA... 8 2. AINEISTO...
 Sisällysluettelo ESIPUHE... 4 ALKUSANAT E-KIRJA VERSIOON... SISÄLLYSLUETTELO... 6 1. METODOLOGIAN PERUSTEIDEN KERTAUSTA... 8 1.1 KESKEISTEN KÄSITTEIDEN KERTAUSTA...9 1.2 AIHEESEEN PEREHTYMINEN...9 1.3
Sisällysluettelo ESIPUHE... 4 ALKUSANAT E-KIRJA VERSIOON... SISÄLLYSLUETTELO... 6 1. METODOLOGIAN PERUSTEIDEN KERTAUSTA... 8 1.1 KESKEISTEN KÄSITTEIDEN KERTAUSTA...9 1.2 AIHEESEEN PEREHTYMINEN...9 1.3
MTTTP5, luento Otossuureita ja niiden jakaumia (jatkuu)
") 21.11.2017/1 MTTTP5, luento 21.11.2017 Otossuureita ja niiden jakaumia (jatkuu) 4) Olkoot X 1, X 2,..., X n satunnaisotos (, ):sta ja Y 1, Y 2,..., Y m satunnaisotos (, ):sta sekä otokset riippumattomia.
21.11.2017/1 MTTTP5, luento 21.11.2017 Otossuureita ja niiden jakaumia (jatkuu) 4) Olkoot X 1, X 2,..., X n satunnaisotos (, ):sta ja Y 1, Y 2,..., Y m satunnaisotos (, ):sta sekä otokset riippumattomia.
Teema 8: Parametrien estimointi ja luottamusvälit
 Teema 8: Parametrien estimointi ja luottamusvälit Todennäköisyyslaskennan perusteet (Teemat 6 ja 7) antavat hyvän pohjan siirtyä kurssin viimeiseen laajempaan kokonaisuuteen, nimittäin tilastolliseen päättelyyn.
Teema 8: Parametrien estimointi ja luottamusvälit Todennäköisyyslaskennan perusteet (Teemat 6 ja 7) antavat hyvän pohjan siirtyä kurssin viimeiseen laajempaan kokonaisuuteen, nimittäin tilastolliseen päättelyyn.
Esim. Pulssi-muuttujan frekvenssijakauma, aineisto luentomoniste liite 4
 18.9.2018/1 MTTTP1, luento 18.9.2018 KERTAUSTA Esim. Pulssi-muuttujan frekvenssijakauma, aineisto luentomoniste liite 4 pyöristetyt todelliset luokka- frekvenssi luokkarajat luokkarajat keskus 42 52 41,5
18.9.2018/1 MTTTP1, luento 18.9.2018 KERTAUSTA Esim. Pulssi-muuttujan frekvenssijakauma, aineisto luentomoniste liite 4 pyöristetyt todelliset luokka- frekvenssi luokkarajat luokkarajat keskus 42 52 41,5
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi. Viikko 5
 MS-A Todennäköisyyslaskennan ja tilastotieteen peruskurssi Viikko Tilastollinen testaus Tilastollisten testaaminen Tilastollisen tutkimuksen kohteena olevasta perusjoukosta on esitetty jokin väite tai
MS-A Todennäköisyyslaskennan ja tilastotieteen peruskurssi Viikko Tilastollinen testaus Tilastollisten testaaminen Tilastollisen tutkimuksen kohteena olevasta perusjoukosta on esitetty jokin väite tai
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 3. marraskuuta 2007 Antti Rasila () TodB 3. marraskuuta 2007 1 / 18 1 Varianssin luottamusväli, jatkoa 2 Bernoulli-jakauman odotusarvon luottamusväli 3
Sovellettu todennäköisyyslaskenta B Antti Rasila 3. marraskuuta 2007 Antti Rasila () TodB 3. marraskuuta 2007 1 / 18 1 Varianssin luottamusväli, jatkoa 2 Bernoulli-jakauman odotusarvon luottamusväli 3
TUTKIMUSAINEISTON ANALYYSI. LTKY012 Timo Törmäkangas
 TUTKIMUSAINEISTON ANALYYSI LTKY012 Timo Törmäkangas f 332 = 3 Kvartiilit(302, 365, 413) Kvartiilit: missä sijaitsee keskimmäinen 50 % aineistosta? Kvartiilit(302, 365, 413) Keskiarvo (362.2) Keskiarvo
TUTKIMUSAINEISTON ANALYYSI LTKY012 Timo Törmäkangas f 332 = 3 Kvartiilit(302, 365, 413) Kvartiilit: missä sijaitsee keskimmäinen 50 % aineistosta? Kvartiilit(302, 365, 413) Keskiarvo (362.2) Keskiarvo
Normaalijakaumasta johdettuja jakaumia
 Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2007) 1 Normaalijakaumasta johdettuja jakaumia >> Johdanto χ 2 -jakauma F-jakauma
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Normaalijakaumasta johdettuja jakaumia TKK (c) Ilkka Mellin (2007) 1 Normaalijakaumasta johdettuja jakaumia >> Johdanto χ 2 -jakauma F-jakauma
r = 0.221 n = 121 Tilastollista testausta varten määritetään aluksi hypoteesit.
 A. r = 0. n = Tilastollista testausta varten määritetään aluksi hypoteesit. H 0 : Korrelaatiokerroin on nolla. H : Korrelaatiokerroin on nollasta poikkeava. Tarkastetaan oletukset: - Kirjoittavat väittävät
A. r = 0. n = Tilastollista testausta varten määritetään aluksi hypoteesit. H 0 : Korrelaatiokerroin on nolla. H : Korrelaatiokerroin on nollasta poikkeava. Tarkastetaan oletukset: - Kirjoittavat väittävät
KURSSIKYSELYAINEISTO: HUOM! Aineiston tilastoyksikkömäärä 11 on kovin pieni oikean tilastotieteen tekemiseen, mutta Harjoitteluun se kelpaa kyllä!
 VAASAN YLIOPISTO/KESÄYLIOPISTO TILASTOTIETEEN PERUSTEET Harjoituksia A KURSSIKYSELYAINEISTO: HUOM! Aineiston tilastoyksikkömäärä 11 on kovin pieni oikean tilastotieteen tekemiseen, mutta Harjoitteluun
VAASAN YLIOPISTO/KESÄYLIOPISTO TILASTOTIETEEN PERUSTEET Harjoituksia A KURSSIKYSELYAINEISTO: HUOM! Aineiston tilastoyksikkömäärä 11 on kovin pieni oikean tilastotieteen tekemiseen, mutta Harjoitteluun
Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (005) 1 Testit suhdeasteikollisille muuttujille Testit normaalijakauman parametreille Yhden otoksen t-testi Kahden
Johdatus tilastotieteeseen Testit suhdeasteikollisille muuttujille TKK (c) Ilkka Mellin (005) 1 Testit suhdeasteikollisille muuttujille Testit normaalijakauman parametreille Yhden otoksen t-testi Kahden
Jos nyt on saatu havaintoarvot Ü ½ Ü Ò niin suurimman uskottavuuden
 1.12.2006 1. Satunnaisjakauman tiheysfunktio on Ü µ Üe Ü, kun Ü ja kun Ü. Määritä parametrin estimaattori momenttimenetelmällä ja suurimman uskottavuuden menetelmällä. Ratkaisu: Jotta kyseessä todella
1.12.2006 1. Satunnaisjakauman tiheysfunktio on Ü µ Üe Ü, kun Ü ja kun Ü. Määritä parametrin estimaattori momenttimenetelmällä ja suurimman uskottavuuden menetelmällä. Ratkaisu: Jotta kyseessä todella
3.6 Su-estimaattorien asymptotiikka
 3.6 Su-estimaattorien asymptotiikka su-estimaattorit ovat usein olleet puutteellisia : ne ovat usein harhaisia ja eikä ne välttämättä ole täystehokkaita asymptoottisilta ominaisuuksiltaan ne ovat yleensä
3.6 Su-estimaattorien asymptotiikka su-estimaattorit ovat usein olleet puutteellisia : ne ovat usein harhaisia ja eikä ne välttämättä ole täystehokkaita asymptoottisilta ominaisuuksiltaan ne ovat yleensä
9. laskuharjoituskierros, vko 12-13, ratkaisut
 9. laskuharjoituskierros, vko 12-13, ratkaisut D1. Olkoot X i, i = 1, 2,..., n riippumattomia, samaa eksponenttijakaumaa noudattavia satunnaismuuttujia, joiden odotusarvo E(X i = β, toisin sanoen X i :t
9. laskuharjoituskierros, vko 12-13, ratkaisut D1. Olkoot X i, i = 1, 2,..., n riippumattomia, samaa eksponenttijakaumaa noudattavia satunnaismuuttujia, joiden odotusarvo E(X i = β, toisin sanoen X i :t
MONISTE 2 Kirjoittanut Elina Katainen
 MONISTE 2 Kirjoittanut Elina Katainen TILASTOLLISTEN MUUTTUJIEN TYYPIT 1 Mitta-asteikot Tilastolliset muuttujat voidaan jakaa kahteen päätyyppiin: kategorisiin ja numeerisiin muuttujiin. Tämän lisäksi
MONISTE 2 Kirjoittanut Elina Katainen TILASTOLLISTEN MUUTTUJIEN TYYPIT 1 Mitta-asteikot Tilastolliset muuttujat voidaan jakaa kahteen päätyyppiin: kategorisiin ja numeerisiin muuttujiin. Tämän lisäksi
4. Seuraavaan ristiintaulukkoon on kerätty tehtaassa valmistettujen toimivien ja ei-toimivien leikkijunien lukumäärät eri työvuoroissa:
 Lisätehtäviä (siis vanhoja tenttikysymyksiä) 1. Erään yrityksen satunnaisesti valittujen työntekijöiden poissaolopäivien määrät olivat vuonna 003: 5, 3, 16, 9, 0, 1, 3,, 19, 5, 19, 11,, 0, 4, 6, 1, 15,
Lisätehtäviä (siis vanhoja tenttikysymyksiä) 1. Erään yrityksen satunnaisesti valittujen työntekijöiden poissaolopäivien määrät olivat vuonna 003: 5, 3, 16, 9, 0, 1, 3,, 19, 5, 19, 11,, 0, 4, 6, 1, 15,
MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 4A Parametrien estimointi Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy 2016, periodi
MS-A0502 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 4A Parametrien estimointi Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy 2016, periodi
/1. MTTTP1, luento Normaalijakauma (kertausta) Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti:
 Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti:") 2.10.2018/1 MTTTP1, luento 2.10.2018 7.4 Normaalijakauma (kertausta) Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti: Samoin z /2 siten, että P(Z > z /2 ) = /2, graafisesti: 2.10.2018/2
2.10.2018/1 MTTTP1, luento 2.10.2018 7.4 Normaalijakauma (kertausta) Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti: Samoin z /2 siten, että P(Z > z /2 ) = /2, graafisesti: 2.10.2018/2
7.4 Normaalijakauma (kertausta ja täydennystä) Taulukosta P(Z 1,6449) = 0,05, P(Z -1,6449) = 0,05 P(Z 1,96) = 0,025, P(Z -1,96) = 0,025
 Taulukosta P(Z 1,6449) = 0,05, P(Z -1,6449) = 0,05 P(Z 1,96) = 0,025, P(Z -1,96) = 0,025") 26.3.2019/1 MTTTP1, luento 26.3.2019 7.4 Normaalijakauma (kertausta ja täydennystä) Z ~ N(0, 1), tiheysfunktion kuvaaja 0,5 0,4 0,3 0,2 0,1 Taulukosta P(Z 1,6449) = 0,05, P(Z -1,6449) = 0,05 P(Z 1,96)
26.3.2019/1 MTTTP1, luento 26.3.2019 7.4 Normaalijakauma (kertausta ja täydennystä) Z ~ N(0, 1), tiheysfunktion kuvaaja 0,5 0,4 0,3 0,2 0,1 Taulukosta P(Z 1,6449) = 0,05, P(Z -1,6449) = 0,05 P(Z 1,96)
Estimointi populaation tuntemattoman parametrin arviointia otossuureen avulla Otossuure satunnaisotoksen avulla määritelty funktio
 17.11.2015/1 MTTTP5, luento 17.11.2015 Luku 5 Parametrien estimointi 5.1 Piste-estimointi Estimointi populaation tuntemattoman parametrin arviointia otossuureen avulla Otossuure satunnaisotoksen avulla
17.11.2015/1 MTTTP5, luento 17.11.2015 Luku 5 Parametrien estimointi 5.1 Piste-estimointi Estimointi populaation tuntemattoman parametrin arviointia otossuureen avulla Otossuure satunnaisotoksen avulla
Jos nollahypoteesi pitää paikkansa on F-testisuuren jakautunut Fisherin F-jakauman mukaan
 17.11.2006 1. Kahdesta kohteesta (A ja K) kerättiin maanäytteitä ja näistä mitattiin SiO -pitoisuus. Tulokset (otoskoot ja otosten tunnusluvut): A K 10 16 Ü 64.94 57.06 9.0 7.29 Oletetaan mittaustulosten
17.11.2006 1. Kahdesta kohteesta (A ja K) kerättiin maanäytteitä ja näistä mitattiin SiO -pitoisuus. Tulokset (otoskoot ja otosten tunnusluvut): A K 10 16 Ü 64.94 57.06 9.0 7.29 Oletetaan mittaustulosten
/1. MTTTP1, luento Normaalijakauma (jatkoa) Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti:
 Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti:") 4.10.2016/1 MTTTP1, luento 4.10.2016 7.4 Normaalijakauma (jatkoa) Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti: Samoin z /2 siten, että P(Z > z /2 ) = /2, graafisesti: 4.10.2016/2
4.10.2016/1 MTTTP1, luento 4.10.2016 7.4 Normaalijakauma (jatkoa) Olkoon Z ~ N(0, 1). Määritellään z siten, että P(Z > z ) =, graafisesti: Samoin z /2 siten, että P(Z > z /2 ) = /2, graafisesti: 4.10.2016/2
MS-A0503 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0503 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 3B Tilastolliset datajoukot Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Lukuvuosi 2016
MS-A0503 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 3B Tilastolliset datajoukot Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Lukuvuosi 2016
MS-A0503 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0503 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 3B Tilastolliset datajoukot Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Lukuvuosi 2016
MS-A0503 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 3B Tilastolliset datajoukot Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Lukuvuosi 2016
Pylväsdiagrammi Suomen kunnat lääneittäin vuonna Piirakkadiagrammi Suomen kunnat lääneittäin vuonna 2003 LKM 14.8% 11.2% 19.7% 4.9% 3.6% 45.
 Pylväsdiagrammi Suomen kunnat lääneittäin vuonna Piirakkadiagrammi Suomen kunnat lääneittäin vuonna 8.8% 8.9%.%.% 9.7%.7% Etelä Länsi Itä Oulu Lappi Ahvenanmaa Länsi Etelä Itä Oulu Lappi Ahvenanmaa Läänien
Pylväsdiagrammi Suomen kunnat lääneittäin vuonna Piirakkadiagrammi Suomen kunnat lääneittäin vuonna 8.8% 8.9%.%.% 9.7%.7% Etelä Länsi Itä Oulu Lappi Ahvenanmaa Länsi Etelä Itä Oulu Lappi Ahvenanmaa Läänien
3.11.2006. ,ܾ jaü on annettu niin voidaan hakea funktion 0.1 0.2 0.3 0.4
 Ü µ ½ ¾Ü¾µ Ü¾Ê 3.11.2006 1. Satunnaismuuttujan tiheysfunktio on ¼ ļ ܽ ܾ ÜÒµ Ä Ü½ ÜÒµ Ò Ä Ü½ ܾ ÜÒµ ܽ µ ܾ µ ÜÒ µ Ò missä tietenkin vaaditaan, että ¼. Muodosta :n ¾Ä ܽ ÜÒµ Ò ½¾ ܾ Ò ½ ¾Ü¾½µ ½ ¾Ü¾Òµ
Ü µ ½ ¾Ü¾µ Ü¾Ê 3.11.2006 1. Satunnaismuuttujan tiheysfunktio on ¼ ļ ܽ ܾ ÜÒµ Ä Ü½ ÜÒµ Ò Ä Ü½ ܾ ÜÒµ ܽ µ ܾ µ ÜÒ µ Ò missä tietenkin vaaditaan, että ¼. Muodosta :n ¾Ä ܽ ÜÒµ Ò ½¾ ܾ Ò ½ ¾Ü¾½µ ½ ¾Ü¾Òµ
Kvantitatiiviset menetelmät
 Kvantitatiiviset menetelmät HUOM! Tentti pidetään tiistaina.. klo 6-8 Vuorikadulla V0 ls Muuttujien muunnokset Usein empiirisen analyysin yhteydessä tulee tarve muuttaa aineiston muuttujia Esim. syntymävuoden
Kvantitatiiviset menetelmät HUOM! Tentti pidetään tiistaina.. klo 6-8 Vuorikadulla V0 ls Muuttujien muunnokset Usein empiirisen analyysin yhteydessä tulee tarve muuttaa aineiston muuttujia Esim. syntymävuoden
Käytetään satunnaismuuttujaa samoin kuin tilastotieteen puolella:
 8.1 Satunnaismuuttuja Käytetään satunnaismuuttujaa samoin kuin tilastotieteen puolella: Esim. Nopanheitossa (d6) satunnaismuuttuja X kertoo silmäluvun arvon. a) listaa kaikki satunnaismuuttujan arvot b)
8.1 Satunnaismuuttuja Käytetään satunnaismuuttujaa samoin kuin tilastotieteen puolella: Esim. Nopanheitossa (d6) satunnaismuuttuja X kertoo silmäluvun arvon. a) listaa kaikki satunnaismuuttujan arvot b)
ABHELSINKI UNIVERSITY OF TECHNOLOGY
 Tilastollinen testaus Tilastollinen testaus Tilastollisessa testauksessa tutkitaan tutkimuskohteita koskevien oletusten tai väitteiden paikkansapitävyyttä havaintojen avulla. Testattavat oletukset tai
Tilastollinen testaus Tilastollinen testaus Tilastollisessa testauksessa tutkitaan tutkimuskohteita koskevien oletusten tai väitteiden paikkansapitävyyttä havaintojen avulla. Testattavat oletukset tai
Kvantitatiiviset tutkimusmenetelmät maantieteessä
 Kvantitatiiviset tutkimusmenetelmät maantieteessä Harjoitukset: 2 Muuttujan normaaliuden testaaminen, merkitsevyys tasot ja yhden otoksen testit FT Joni Vainikka, Yliopisto-opettaja, GO218, joni.vainikka@oulu.fi
Kvantitatiiviset tutkimusmenetelmät maantieteessä Harjoitukset: 2 Muuttujan normaaliuden testaaminen, merkitsevyys tasot ja yhden otoksen testit FT Joni Vainikka, Yliopisto-opettaja, GO218, joni.vainikka@oulu.fi
Esimerkki 1: auringonkukan kasvun kuvailu
 GeoGebran LASKENTATAULUKKO Esimerkki 1: auringonkukan kasvun kuvailu Auringonkukka (Helianthus annuus) on yksivuotinen kasvi, jonka varren pituus voi aurinkoisina kesinä hyvissä kasvuolosuhteissa Suomessakin
GeoGebran LASKENTATAULUKKO Esimerkki 1: auringonkukan kasvun kuvailu Auringonkukka (Helianthus annuus) on yksivuotinen kasvi, jonka varren pituus voi aurinkoisina kesinä hyvissä kasvuolosuhteissa Suomessakin
TUTKIMUSAINEISTON KVANTITATIIVINEN ANALYYSI LTKY012. Timo Törmäkangas
 TUTKIMUSAINEISTON KVANTITATIIVINEN ANALYYSI LTKY012 Timo Törmäkangas KURSSIN SISÄLTÖ Johdanto Mittaaminen ja aineiston hankinta Mitta-asteikot Otanta Aineiston esittäminen ja data-analyysi Havaintomatriisi
TUTKIMUSAINEISTON KVANTITATIIVINEN ANALYYSI LTKY012 Timo Törmäkangas KURSSIN SISÄLTÖ Johdanto Mittaaminen ja aineiston hankinta Mitta-asteikot Otanta Aineiston esittäminen ja data-analyysi Havaintomatriisi
6. laskuharjoitusten vastaukset (viikot 10 11)
") 6. laskuharjoitusten vastaukset (viikot 10 11) 1. a) Sivun 102 hypergeometrisen jakauman määritelmästä saadaan µ µ 13 39 13! 13 12 11 10 9 µ 0! 8! 1! 2 2! 2 1 0 49 48! 47!! 14440 120 31187200 120 1287
6. laskuharjoitusten vastaukset (viikot 10 11) 1. a) Sivun 102 hypergeometrisen jakauman määritelmästä saadaan µ µ 13 39 13! 13 12 11 10 9 µ 0! 8! 1! 2 2! 2 1 0 49 48! 47!! 14440 120 31187200 120 1287
edellyttää valintaa takaisinpanolla Aritmeettinen keskiarvo Jos, ½ Ò muodostavat satunnaisotoksen :n jakaumasta niin Otosvarianssi Ë ¾
 ËØÙ ÓØÓ Ø Mitta-asteikot Nominaali- eli laatueroasteikko Ordinaali- eli järjestysasteikko Intervalli- eli välimatka-asteikko ( nolla mielivaltainen ) Suhdeasteikko ( nolla ei ole mielivaltainen ) Otos
ËØÙ ÓØÓ Ø Mitta-asteikot Nominaali- eli laatueroasteikko Ordinaali- eli järjestysasteikko Intervalli- eli välimatka-asteikko ( nolla mielivaltainen ) Suhdeasteikko ( nolla ei ole mielivaltainen ) Otos
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 6A Tilastolliset luottamusvälit Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy 2016,
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi 6A Tilastolliset luottamusvälit Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto Syksy 2016,
4.1. Olkoon X mielivaltainen positiivinen satunnaismuuttuja, jonka odotusarvo on
 Mat-2.090 Sovellettu todennäköisyyslasku A / Ratkaisut Aiheet: Avainsanat: Otanta Poisson- Jakaumien tunnusluvut Diskreetit jakaumat Binomijakauma, Diskreetti tasainen jakauma, Geometrinen jakauma, Hypergeometrinen
Mat-2.090 Sovellettu todennäköisyyslasku A / Ratkaisut Aiheet: Avainsanat: Otanta Poisson- Jakaumien tunnusluvut Diskreetit jakaumat Binomijakauma, Diskreetti tasainen jakauma, Geometrinen jakauma, Hypergeometrinen
Lisätehtäviä ratkaisuineen luentomonisteen lukuun 6 liittyen., jos otoskeskiarvo on suurempi kuin 13,96. Mikä on testissä käytetty α:n arvo?
 MTTTP5, kevät 2016 15.2.2016/RL Lisätehtäviä ratkaisuineen luentomonisteen lukuun 6 liittyen 1. Valitaan 25 alkion satunnaisotos jakaumasta N(µ, 25). Olkoon H 0 : µ = 12. Hylätään H 0, jos otoskeskiarvo
MTTTP5, kevät 2016 15.2.2016/RL Lisätehtäviä ratkaisuineen luentomonisteen lukuun 6 liittyen 1. Valitaan 25 alkion satunnaisotos jakaumasta N(µ, 25). Olkoon H 0 : µ = 12. Hylätään H 0, jos otoskeskiarvo
χ = Mat Sovellettu todennäköisyyslasku 11. harjoitukset/ratkaisut
 Mat-2.091 Sovellettu todennäköisyyslasku /Ratkaisut Aiheet: Yhteensopivuuden testaaminen Homogeenisuuden testaaminen Riippumattomuuden testaaminen Avainsanat: Estimointi, Havaittu frekvenssi, Homogeenisuus,
Mat-2.091 Sovellettu todennäköisyyslasku /Ratkaisut Aiheet: Yhteensopivuuden testaaminen Homogeenisuuden testaaminen Riippumattomuuden testaaminen Avainsanat: Estimointi, Havaittu frekvenssi, Homogeenisuus,
14 Jatkuva jakauma. Käsitellään kuitenkin ennen täsmällisiä määritelmiä johdatteleva
 4 Jatkuva jakauma Edellä määriteltiin diskreetiksi satunnaismuuttujaksi sellainen, joka voi saada vain (hyppäyksittäin) erillisiä arvoja. Jatkuva satunnaismuuttuja voi saada mitä hyvänsä arvoja yleensä
4 Jatkuva jakauma Edellä määriteltiin diskreetiksi satunnaismuuttujaksi sellainen, joka voi saada vain (hyppäyksittäin) erillisiä arvoja. Jatkuva satunnaismuuttuja voi saada mitä hyvänsä arvoja yleensä
Lisää Diskreettejä jakaumia Lisää Jatkuvia jakaumia Normaalijakaumasta johdettuja jakaumia
 Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Lisää Diskreettejä jakaumia Lisää Jatkuvia jakaumia Normaalijakaumasta johdettuja jakaumia KE (2014) 1 Hypergeometrinen jakauma Hypergeometrinen jakauma
Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Lisää Diskreettejä jakaumia Lisää Jatkuvia jakaumia Normaalijakaumasta johdettuja jakaumia KE (2014) 1 Hypergeometrinen jakauma Hypergeometrinen jakauma
Ilkka Mellin Todennäköisyyslaskenta. Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat. Kertymäfunktio. TKK (c) Ilkka Mellin (2007) 1
 Ilkka Mellin (2007) 1") Ilkka Mellin Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Kertymäfunktio TKK (c) Ilkka Mellin (2007) 1 Kertymäfunktio >> Kertymäfunktio: Määritelmä Diskreettien jakaumien
Ilkka Mellin Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Kertymäfunktio TKK (c) Ilkka Mellin (2007) 1 Kertymäfunktio >> Kertymäfunktio: Määritelmä Diskreettien jakaumien
Sovellettu todennäköisyyslaskenta B
 Sovellettu todennäköisyyslaskenta B Antti Rasila 8. marraskuuta 2007 Antti Rasila () TodB 8. marraskuuta 2007 1 / 15 1 Tilastollisia testejä Z-testi Normaalijakauman odotusarvon testaus, keskihajonta tunnetaan
Sovellettu todennäköisyyslaskenta B Antti Rasila 8. marraskuuta 2007 Antti Rasila () TodB 8. marraskuuta 2007 1 / 15 1 Tilastollisia testejä Z-testi Normaalijakauman odotusarvon testaus, keskihajonta tunnetaan
MS-A0501 Todennäköisyyslaskennan ja tilastotieteen peruskurssi
 MS-A050 Todennäköisyyslaskennan ja tilastotieteen peruskurssi B Satunnaismuuttujat ja todennäköisyysjakaumat Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto
MS-A050 Todennäköisyyslaskennan ja tilastotieteen peruskurssi B Satunnaismuuttujat ja todennäköisyysjakaumat Lasse Leskelä Matematiikan ja systeemianalyysin laitos Perustieteiden korkeakoulu Aalto-yliopisto
805306A Johdatus monimuuttujamenetelmiin, 5 op
 monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Logistinen regressioanalyysi Vastemuuttuja Y on luokiteltu muuttuja Pyritään mallittamaan havaintoyksikön todennäköisyyttä kuulua
monimuuttujamenetelmiin, 5 op syksy 2018 Matemaattisten tieteiden laitos Logistinen regressioanalyysi Vastemuuttuja Y on luokiteltu muuttuja Pyritään mallittamaan havaintoyksikön todennäköisyyttä kuulua
Todennäköisyyslaskun kertaus. Vilkkumaa / Kuusinen 1
 Todennäköisyyslaskun kertaus Vilkkumaa / Kuusinen 1 Satunnaismuuttujat ja todennäköisyysjakaumat Vilkkumaa / Kuusinen 2 Motivointi Kokeellisessa tutkimuksessa tutkittaviin ilmiöihin liittyvien havaintojen
Todennäköisyyslaskun kertaus Vilkkumaa / Kuusinen 1 Satunnaismuuttujat ja todennäköisyysjakaumat Vilkkumaa / Kuusinen 2 Motivointi Kokeellisessa tutkimuksessa tutkittaviin ilmiöihin liittyvien havaintojen
Johdatus todennäköisyyslaskentaan Kertymäfunktio. TKK (c) Ilkka Mellin (2005) 1
 Ilkka Mellin (2005) 1") Johdatus todennäköisyyslaskentaan Kertymäfunktio TKK (c) Ilkka Mellin (2005) 1 Kertymäfunktio Kertymäfunktio: Määritelmä Diskreettien jakaumien kertymäfunktiot Jatkuvien jakaumien kertymäfunktiot TKK (c)
Johdatus todennäköisyyslaskentaan Kertymäfunktio TKK (c) Ilkka Mellin (2005) 1 Kertymäfunktio Kertymäfunktio: Määritelmä Diskreettien jakaumien kertymäfunktiot Jatkuvien jakaumien kertymäfunktiot TKK (c)
7. laskuharjoituskierros, vko 10, ratkaisut
 7. laskuharjoituskierros, vko 10, ratkaisut D1. a) Oletetaan, että satunnaismuuttujat X ja Y noudattavat kaksiulotteista normaalijakaumaa parametrein E(X) = 0, E(Y ) = 1, Var(X) = 1, Var(Y ) = 4 ja Cov(X,
7. laskuharjoituskierros, vko 10, ratkaisut D1. a) Oletetaan, että satunnaismuuttujat X ja Y noudattavat kaksiulotteista normaalijakaumaa parametrein E(X) = 0, E(Y ) = 1, Var(X) = 1, Var(Y ) = 4 ja Cov(X,
l (φ; y) = l(θ(φ); y) Toinen derivaatta saadaan tulon derivaatan laskusäännöllä Uudelleenparametroidun mallin Fisherin informaatio on
 = l(θ(φ); y) Toinen derivaatta saadaan tulon derivaatan laskusäännöllä Uudelleenparametroidun mallin Fisherin informaatio on") HY, MTO / Matemaattisten tieteiden kandiohjelma Tilastollinen päättely II, kevät 018 Harjoitus B Ratkaisuehdotuksia Tehtäväsarja I 1 (Monisteen tehtävä 14) Olkoon f Y (y; θ) tilastollinen malli, jonka
HY, MTO / Matemaattisten tieteiden kandiohjelma Tilastollinen päättely II, kevät 018 Harjoitus B Ratkaisuehdotuksia Tehtäväsarja I 1 (Monisteen tehtävä 14) Olkoon f Y (y; θ) tilastollinen malli, jonka
Moniulotteisia todennäköisyysjakaumia
 Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (007) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (007) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia
 Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (006) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta Osa 3: Todennäköisyysjakaumia Moniulotteisia todennäköisyysjakaumia TKK (c) Ilkka Mellin (006) 1 Moniulotteisia todennäköisyysjakaumia >> Multinomijakauma Kaksiulotteinen
Ilkka Mellin Todennäköisyyslaskenta. Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat. Jakaumien tunnusluvut. TKK (c) Ilkka Mellin (2007) 1
 Ilkka Mellin (2007) 1") Ilkka Mellin Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Jakaumien tunnusluvut TKK (c) Ilkka Mellin (2007) 1 Jakaumien tunnusluvut >> Odotusarvo Varianssi Markovin ja Tshebyshevin
Ilkka Mellin Todennäköisyyslaskenta Osa 2: Satunnaismuuttujat ja todennäköisyysjakaumat Jakaumien tunnusluvut TKK (c) Ilkka Mellin (2007) 1 Jakaumien tunnusluvut >> Odotusarvo Varianssi Markovin ja Tshebyshevin